어느덧 6주차까지 왔다. 혼공 완주 !!!
스스로에게 칭찬해줘야지 !!! 쓰담~ 쓰담~
▶ 내용 요약
06-1 객체지향 API로 그래프 꾸미기
- pyplot 방식과 객체지향 API 방식

- 그래프에 한글 출력하기
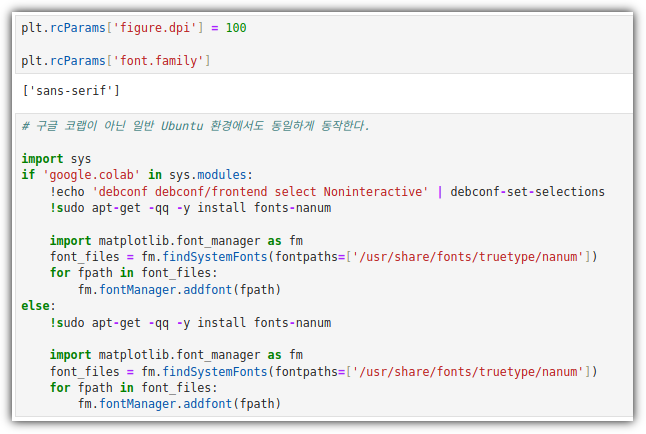
. 한글 폰트가 필요하기 때문에, 나눔폰트를 설치해야 한다.
. 예제에서는 구글 코랩에 대해서만 설명되어 있지만, 일반적인 Ubuntu 환경에서도 적용된다.
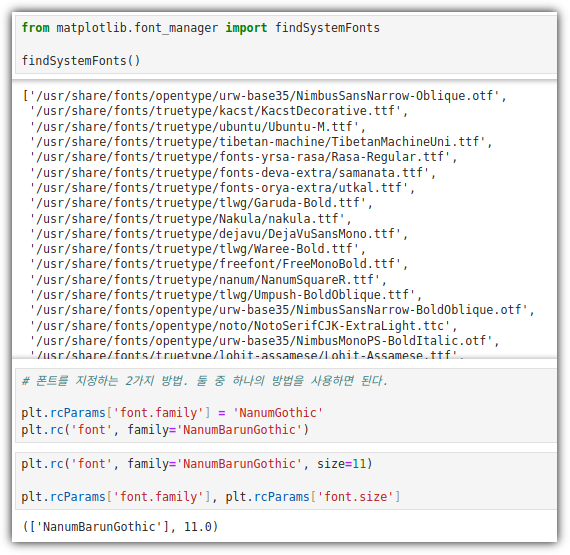
. 사용할 수 있는 폰트 목록을 확인해볼 수도 있다.
. 사용할 폰트를 지정할 수도 있고, 크기도 정할 수 있다.
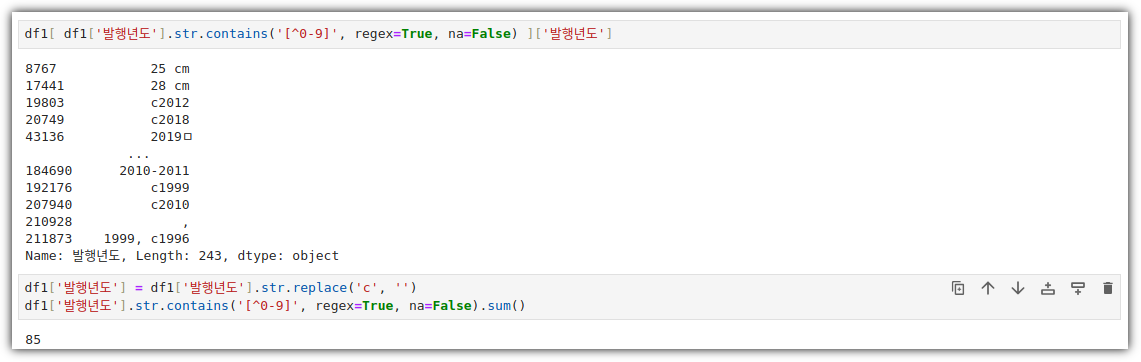
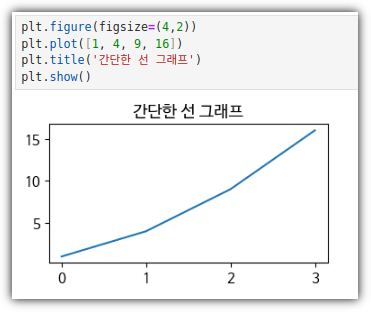
. 잘 되는지 확인해보자.
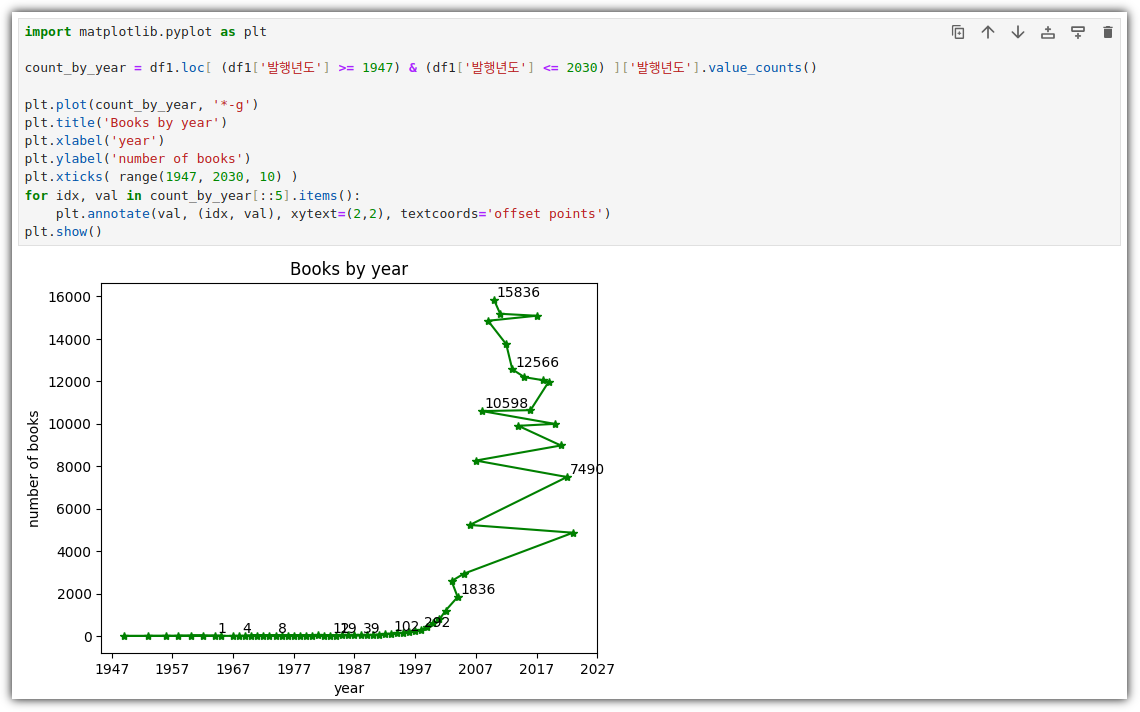
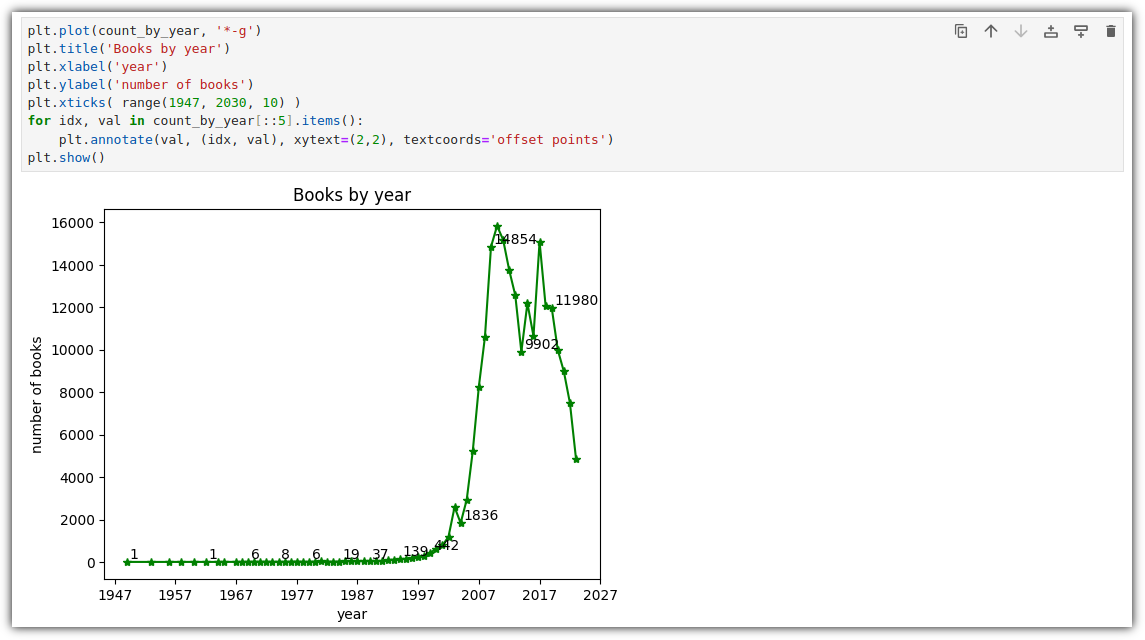
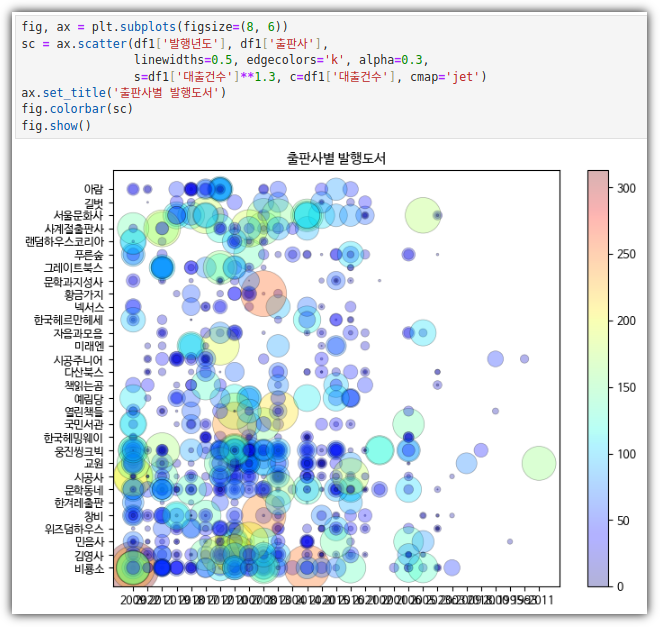
- 출판사별 발행 도서 개수 산점도 그리기
. 교재와는 다르게, 내가 이용하는 도서관의 데이터로 진행해봤다.
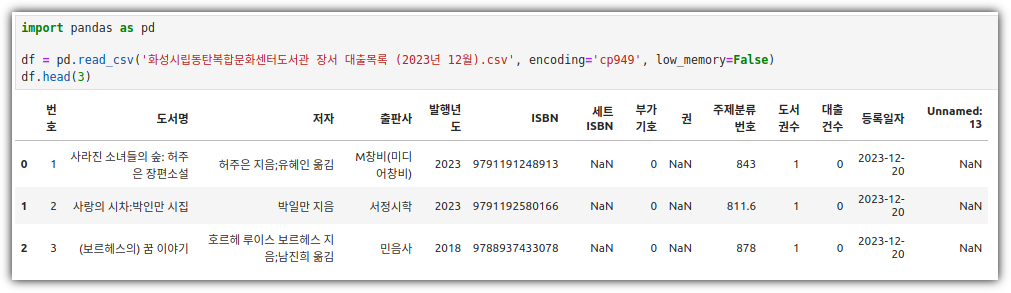
. 모든 데이터가 아닌 Top 30 출판사를 뽑아서 사용한다.

. 산점도를 그리면 된다!
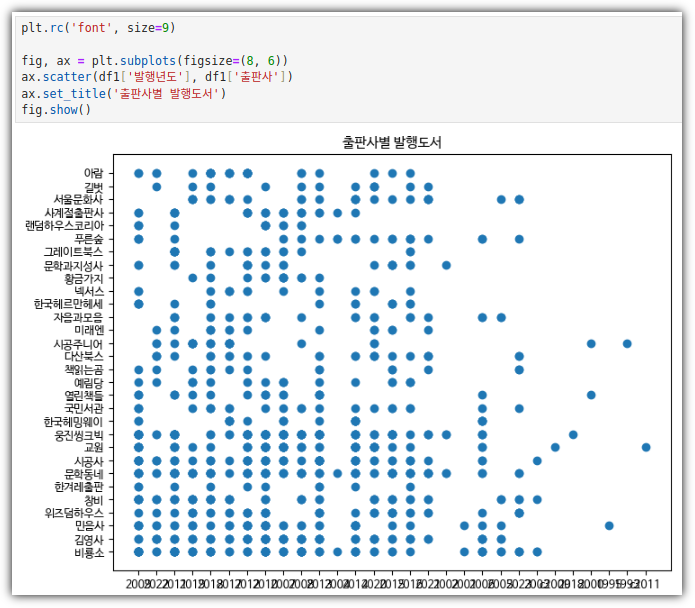
. Marker 크기를 확인하거나 설정을 할 수도 있다.
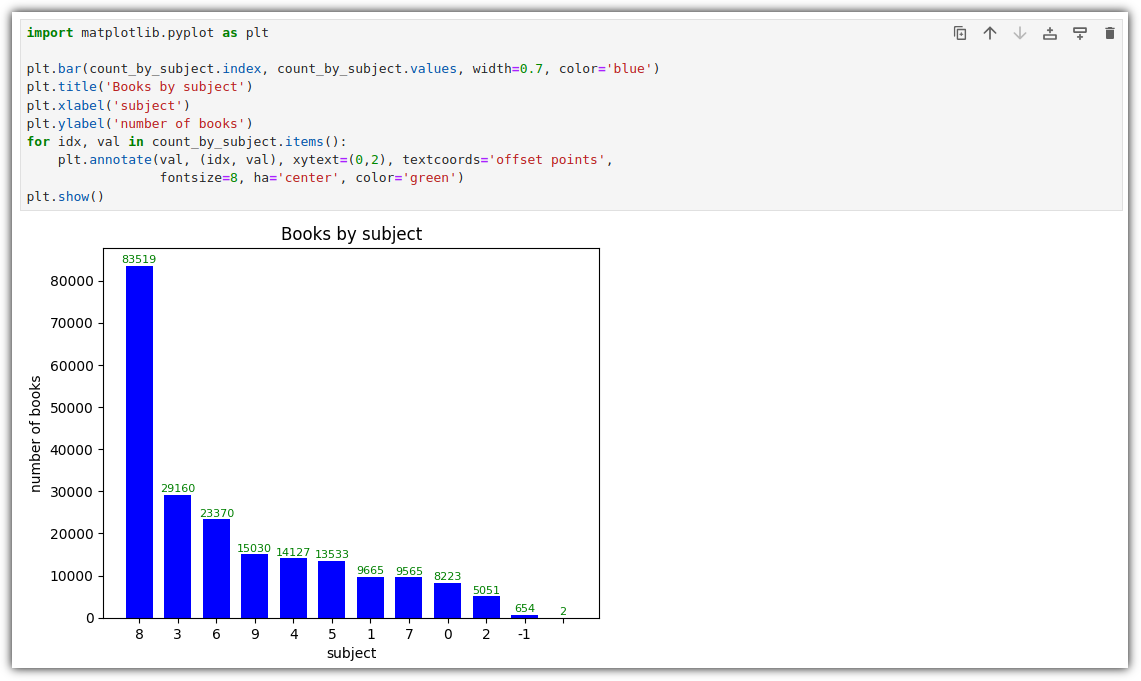
. 그냥 점이 아니라 크기에 따라 의미를 부여해보자. (대출건수)
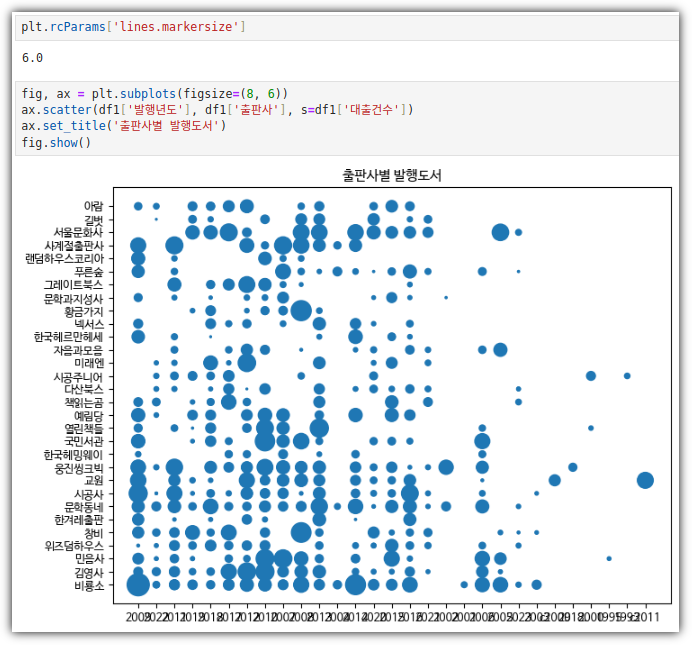
- 맷플롯립의 다양한 기능으로 그래프 개선하기
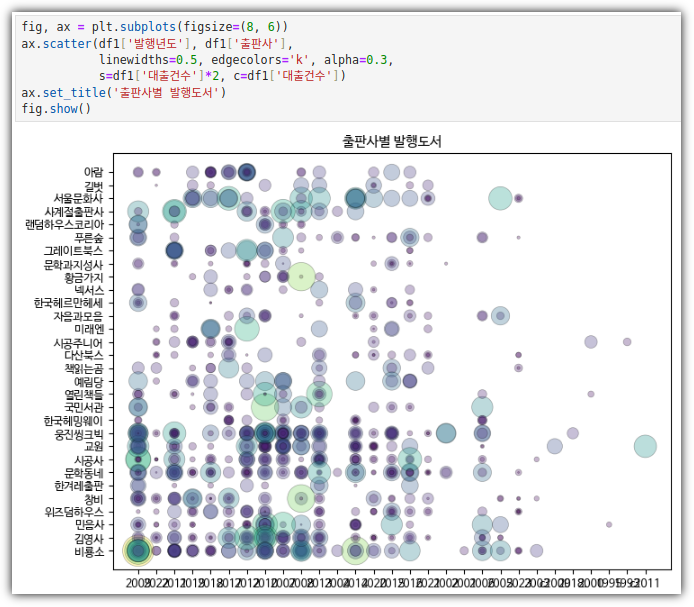
06-2 맷플롯립의 고급 기능 배우기
- 실습준비하기
. 한글 폰트 설치 및 도서관 CSV 파일 읽어오기 (앞에서 진행했던 내용 활용)
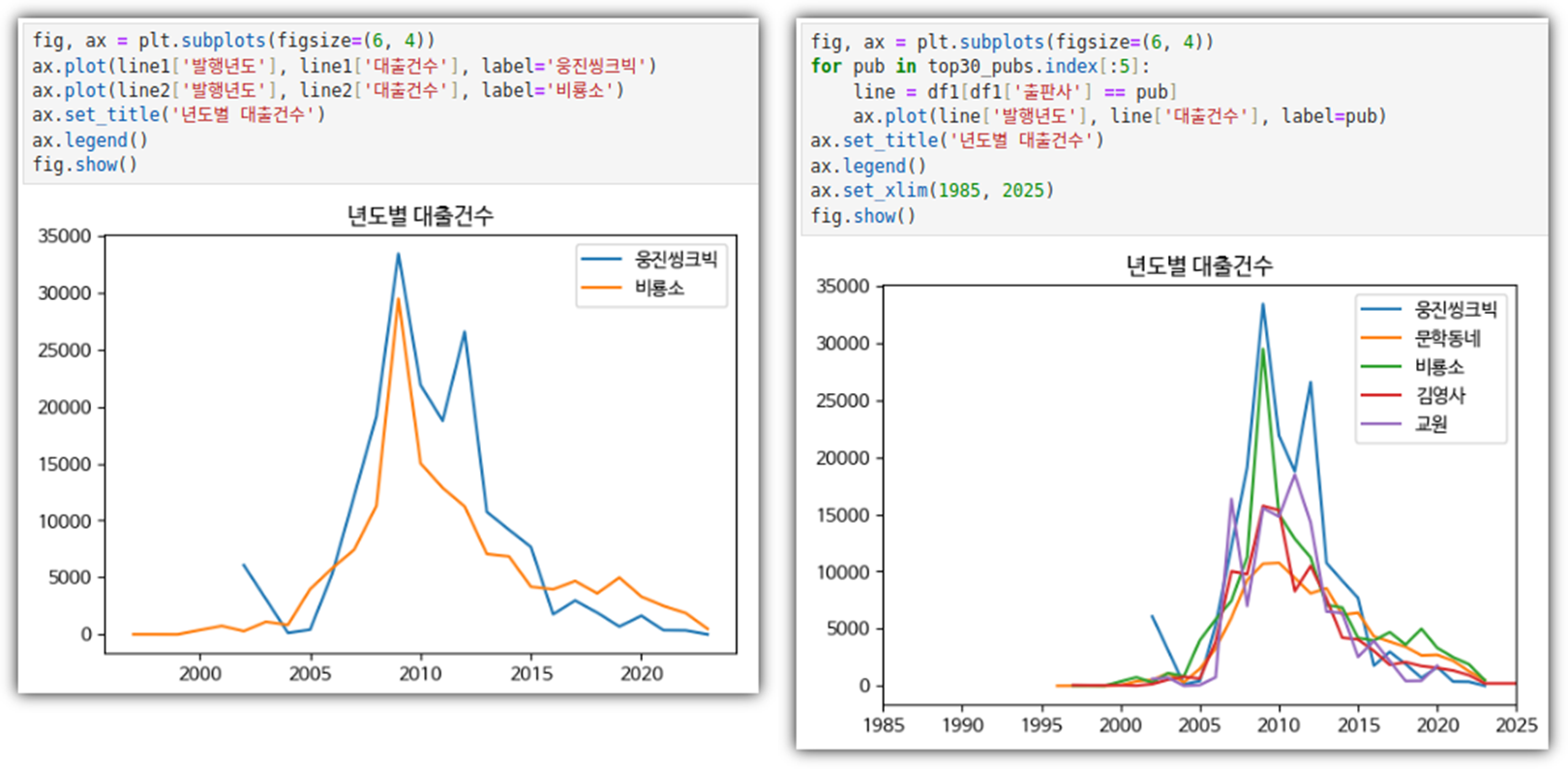
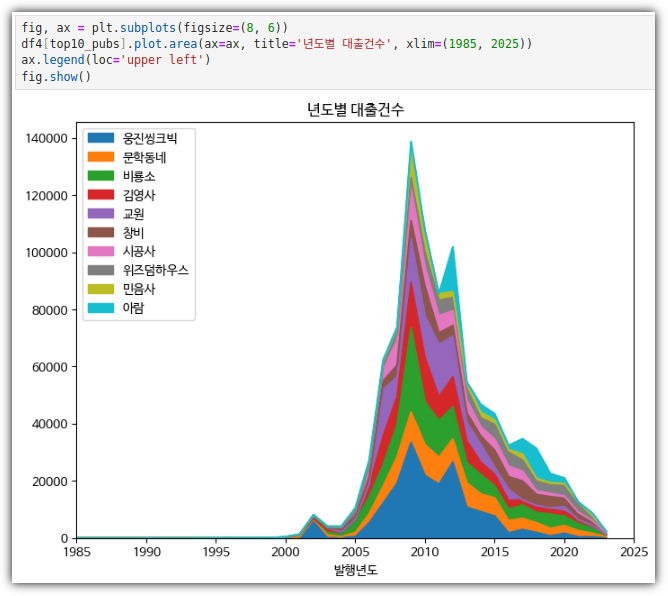
- 하나의 피겨에 여러 개의 선 그래프 그리기
. 대출건수 크기가 유사한 출판사 2개를 선택해서 그려보자

. 레전드를 표현하거나 모든 출판사 정보를 그려보거나 해보자.
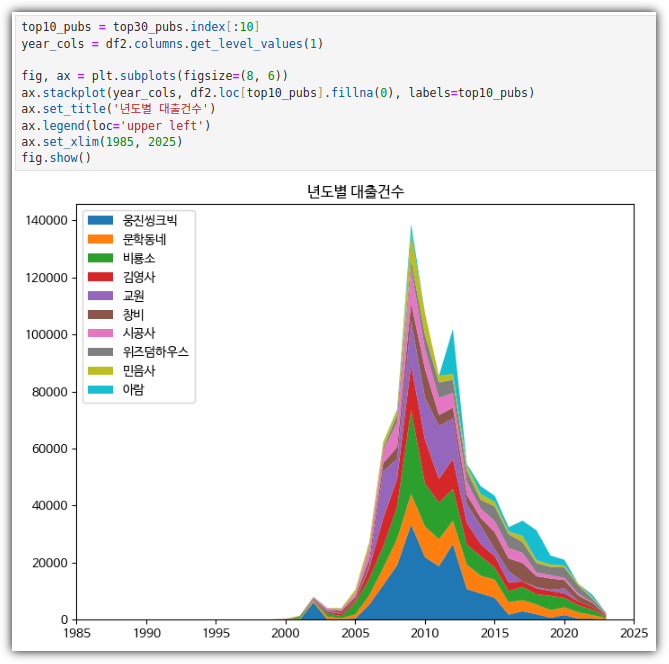
. 피봇 테이블을 이용해서 데이터를 만들어서 stackplot으로 그려보자.
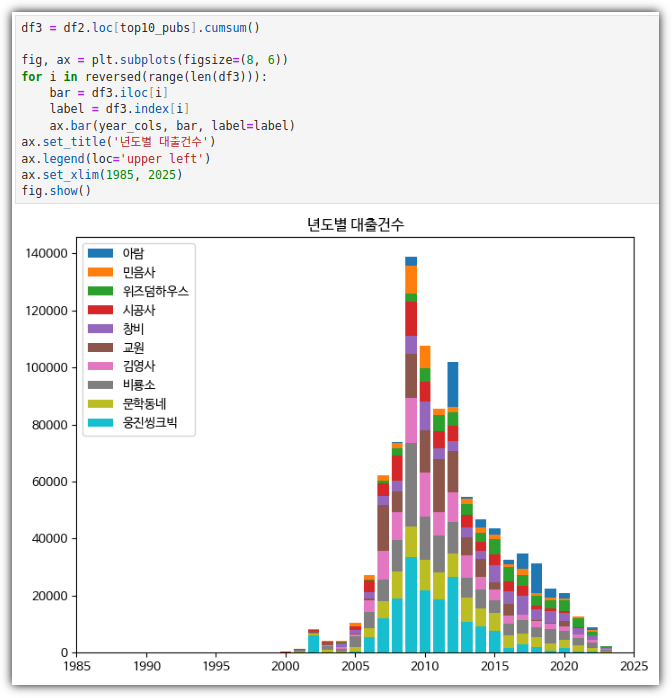
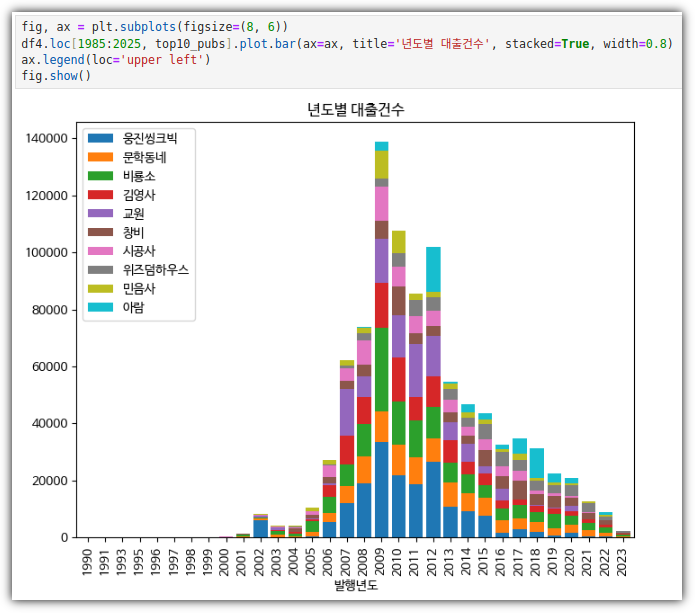
- 하나의 피겨에 여러 개의 막대 그래프 그리기
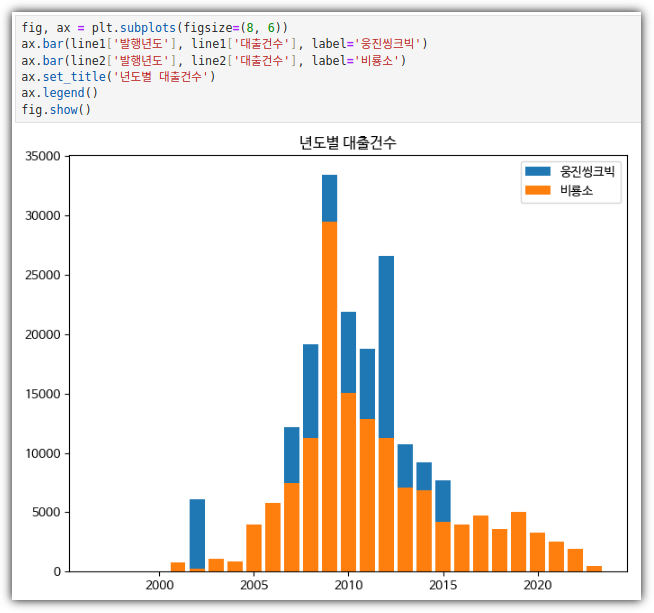
. 나란히 나오도록 할 수도 있다.
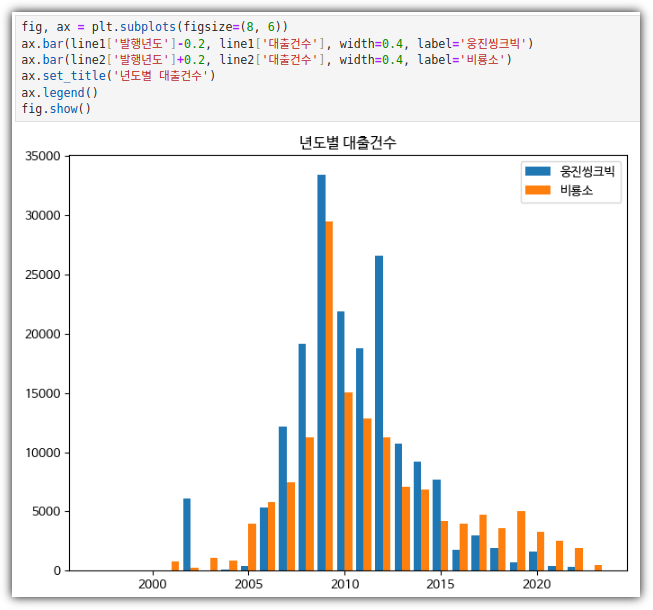
. 2개의 bar 그래프를 합쳐서 그리는 2가지 방법이 있다.
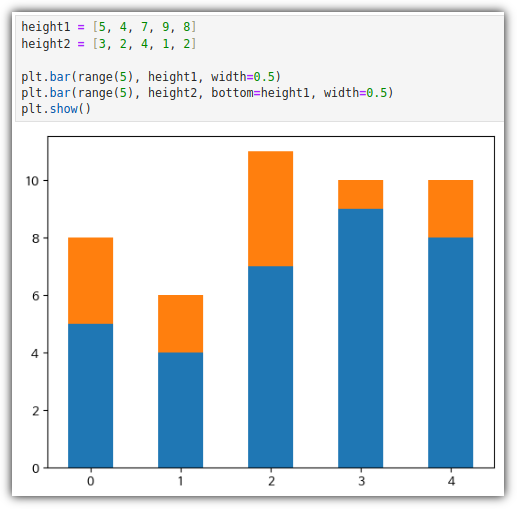
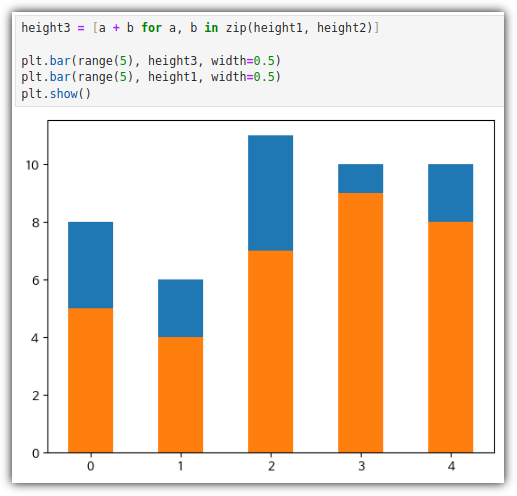
. 데이터 값 누적한 것을 그려보기 위해서 데이터를 먼저 확인해보자
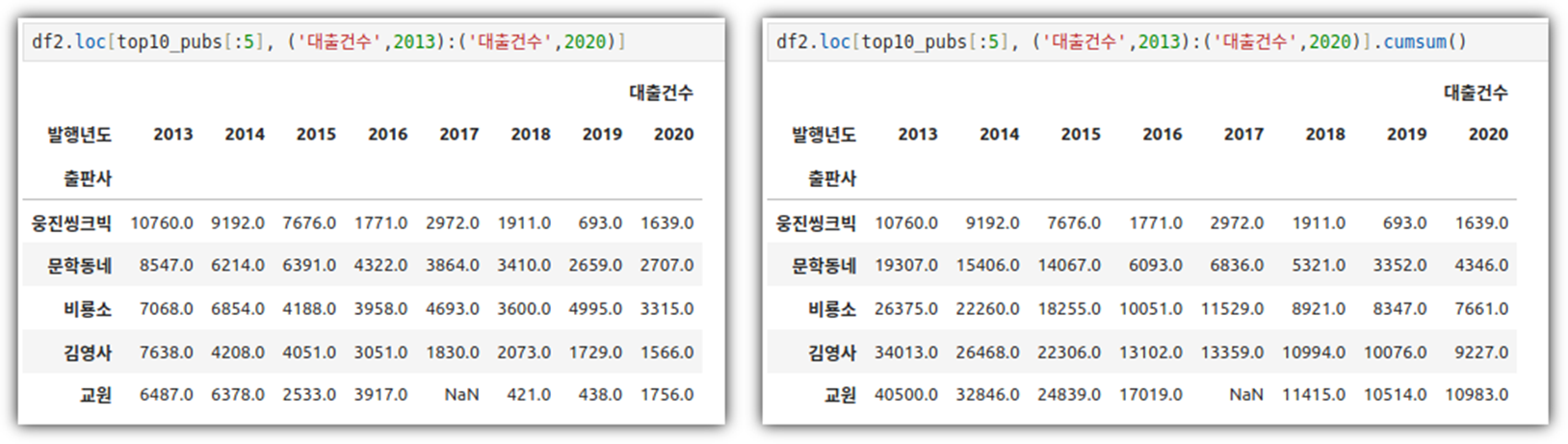
. cumsum()을 이용해서 누적 데이터를 만들 수 있다.
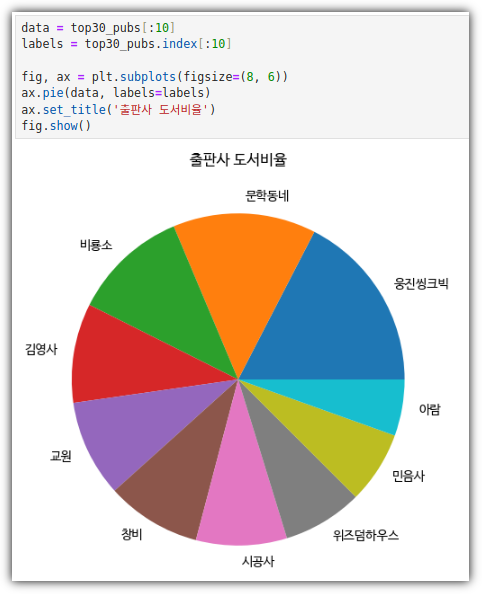
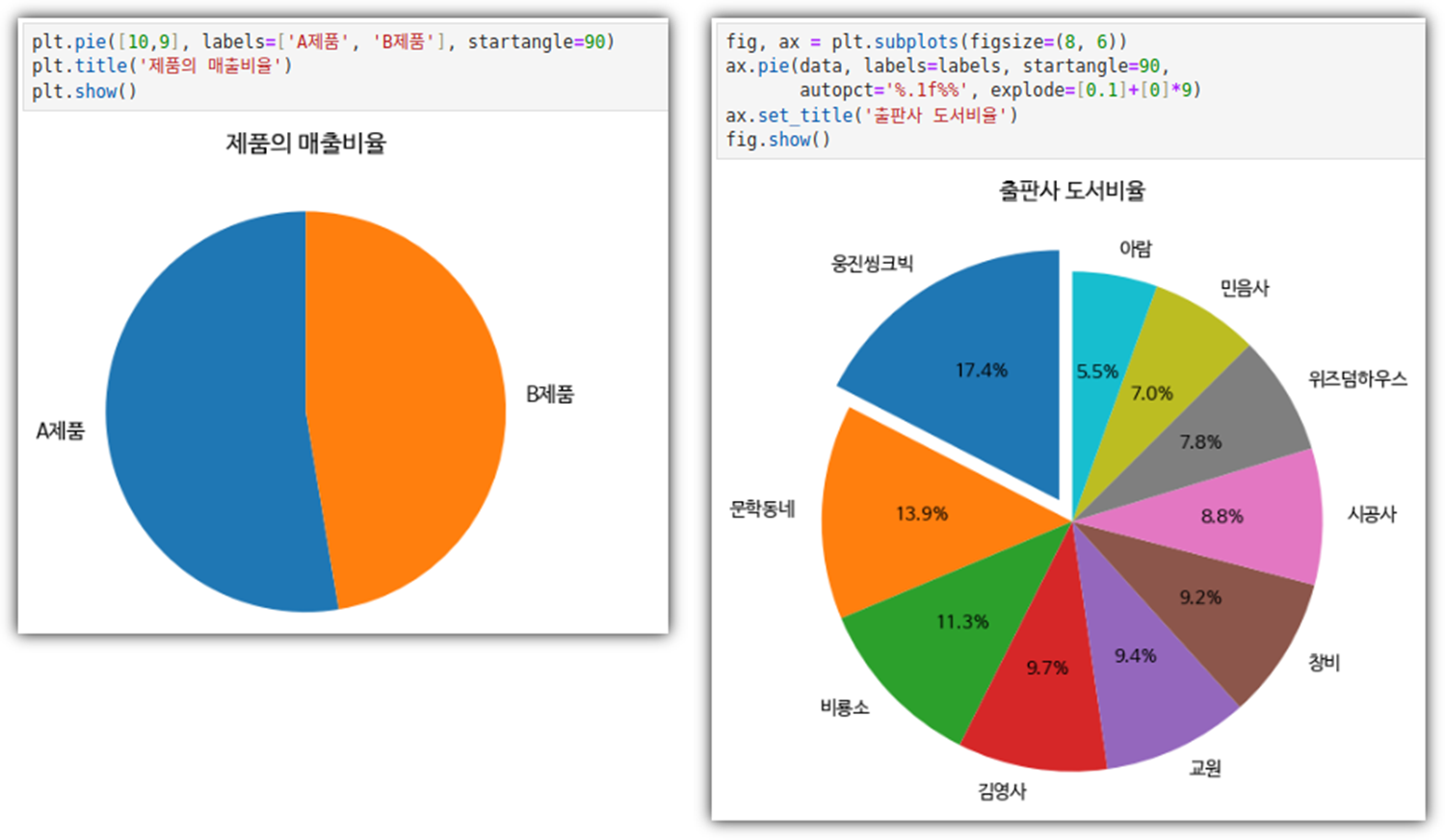
- 원 그래프 그리기
. 10개 출판사를 뽑아서 pie를 그리면 된다.
. startangle 및 여러 옵션들을 줘서 멋진 원 그래프를 만들 수 있다.
- 여러 종류의 그래프가 있는 서브플롯 그리기
. 앞에서 살펴본 것들의 종합판이다!
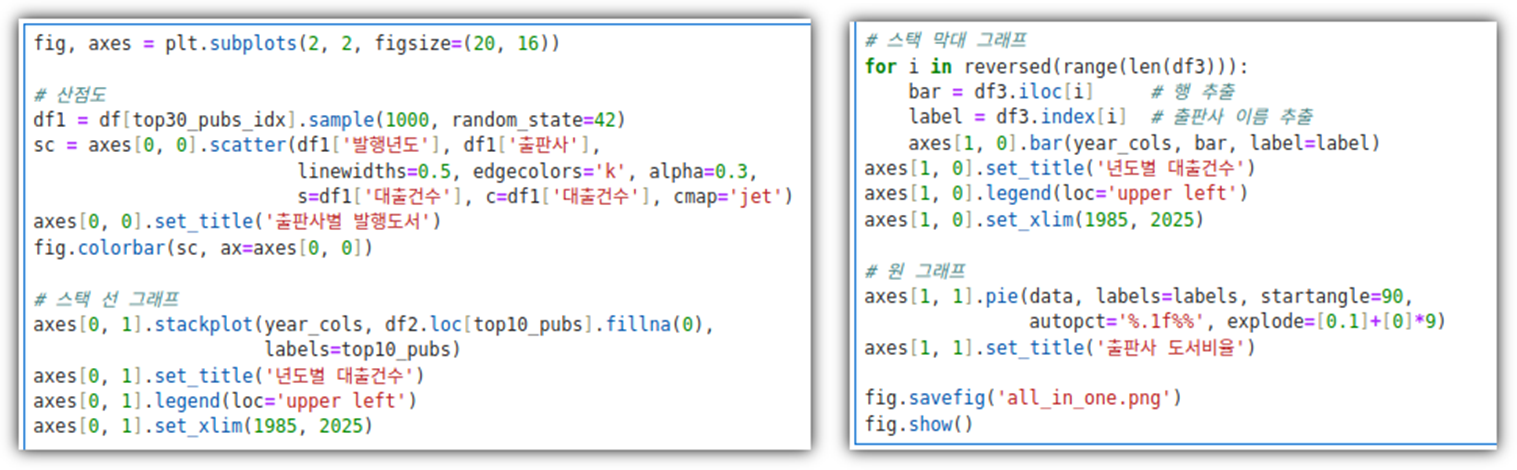
. 한 방에 모두 그려진다!!!

- 판다스로 여러 개의 그래프 그리기
. DataFrame에서 바로 그래프를 그릴 수도 있다.
▶ 기본 미션
p.344의 손코(맷플롯립의 컬러맵으로 산점도 그리기)를 코랩에서 그래프 출력하고 화면 캡쳐하기
→ 코랩이 아닌 로컬 환경에서 실행해봤다 ^^
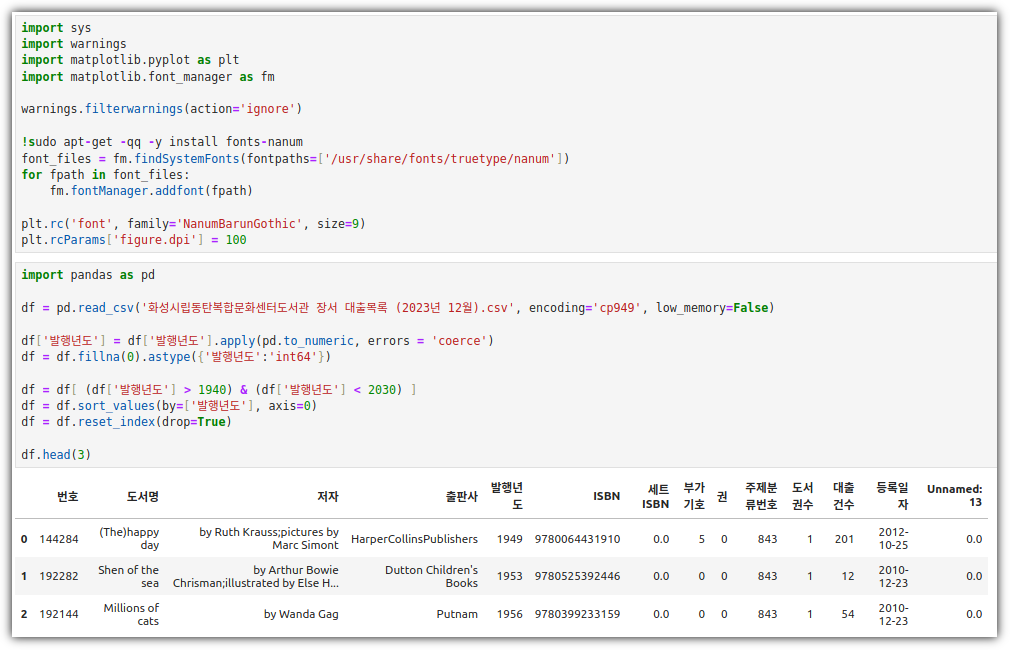
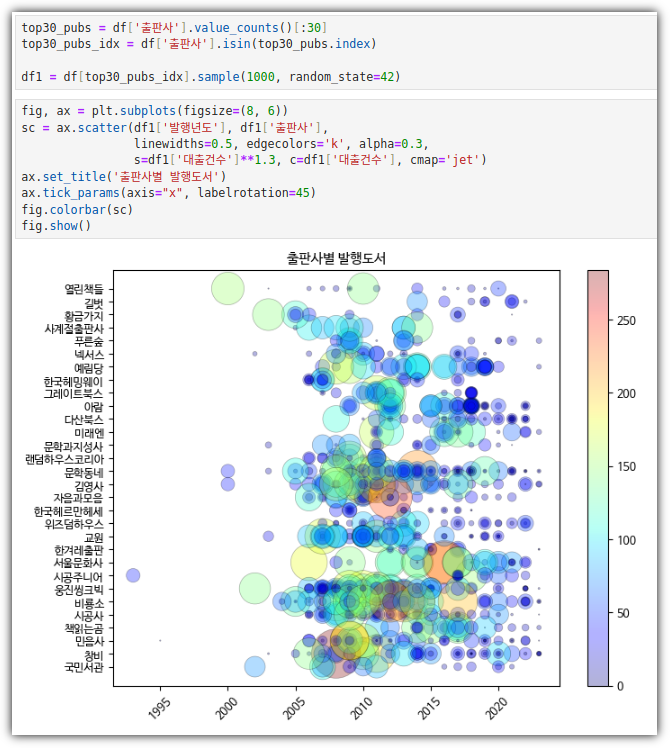
▶ 선택 미션
p.356~359의 스택 영역 그래프를 그리는 과정을 정리하기
① 기본 데이터 준비
- 작업 준비 과정이다.
② 그래프로 표현할 데이터 만들기
- Top30 출판사 기준으로 "출판사 / 발행년도 / 대출건수"를 추출하고,
- "출판사 / 발행년도" 기준으로 그룹핑을 하면서, 대출건수는 sum()을 했다.
- 전체적으로 reset_index()까지 해줬다.
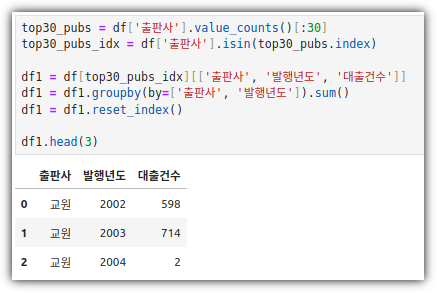
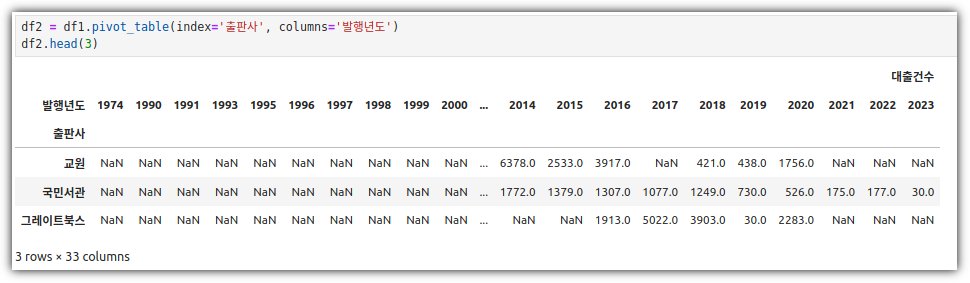
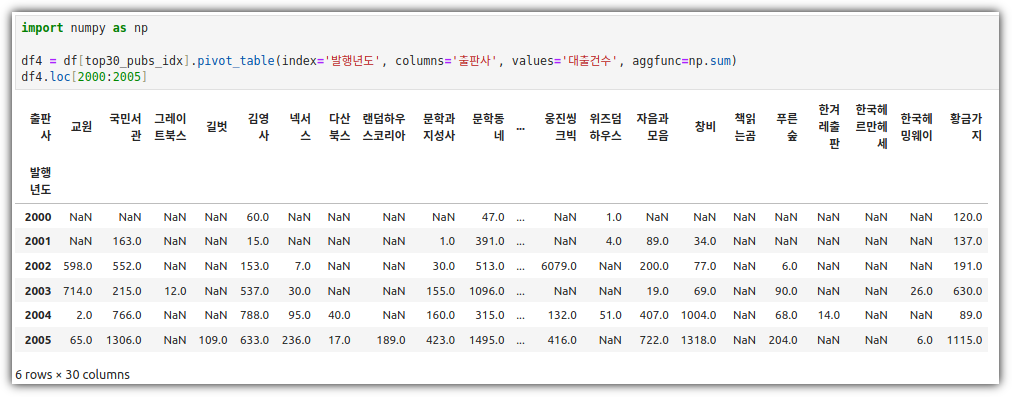
③ pivot_table()
- 발행년도를 X축으로 하고, 출판사를 Y축으로 하고, 대출건수를 데이터로 하는 테이블을 만든다.
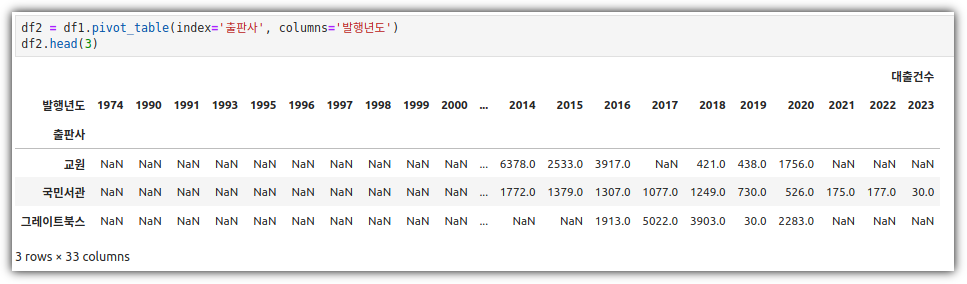
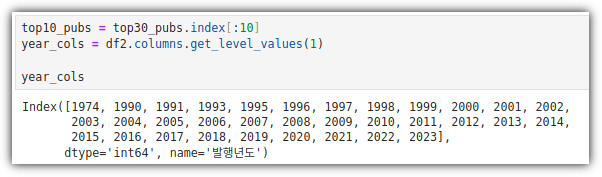
④ get_level_values()
- pivot_table()을 사용했다보니, column이 다단으로 구성되어 있다.
- 이런 경우 원하는 레벨의 값만 추출하기 위해 get_level_values()를 사용했다.
⑤ stackplot()
- 이제 그래프를 그리면 된다.
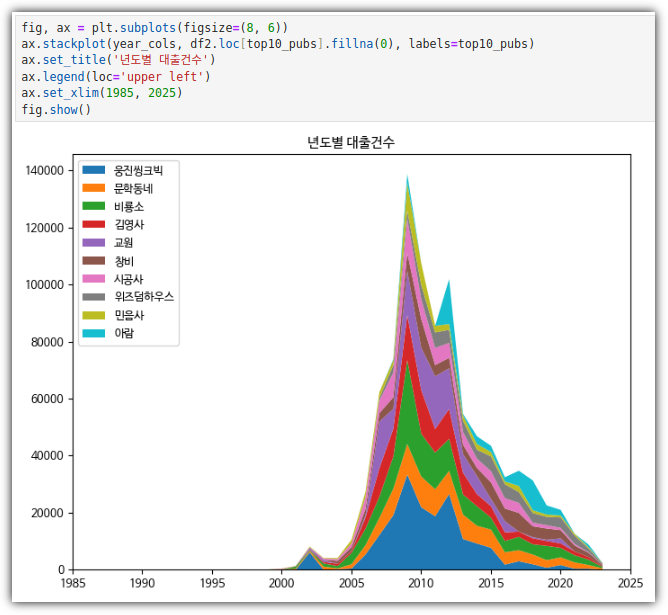
우와~~~ 다했다!!!!
'Books' 카테고리의 다른 글
| [혼공데분] 5주차_데이터 시각화하기 (0) | 2024.02.01 |
|---|---|
| [혼공데분] 4주차_데이터 요약하기 (0) | 2024.01.28 |
| [혼공데분] 3주차_데이터 정제하기 (1) | 2024.01.21 |
| [혼공데분] 2주차_데이터 수집하기 (2) | 2024.01.16 |
| [혼공데분] 1주차_데이터 분석을 시작하며 (1) | 2024.01.07 |