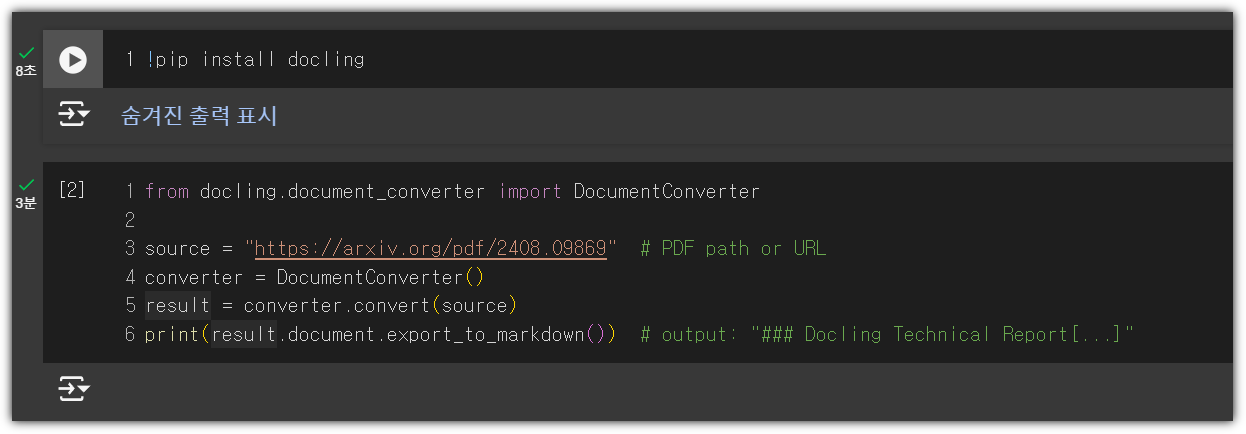
여기에서 해보고 싶은 것은 "동탄" 키워드가 들어간 최근 블로그를 검색해서
그 제목과 본문 내용, 링크 값을 얻어오는 코드를 작성해보고자 한다.
0. 개발 환경
- OS: Ubuntu 20.04
- Lang: Python 3.10.9
1. 준비
① NAVER API를 사용하기 위해 API 키를 생성하자.
② 환경변수를 다루기 위해서 dotenvx를 사용해보자.
- 아는 사람만 쓴다는 Config 관리자 - dotenv, dotenvx
2. 코드 작성
일단 API 호출을 위해 requests 패키지를 사용하기로 했다.
[ requirements.txt ]
requests==2.32.3
가급적 클래스 구조로 작성해봤다.
[ main.py ]
import requests
import os
class BlogPost:
def __init__(self, title, description, link):
self.title = title.replace("<b>", "").replace("</b>", "")
self.description = description.replace("<b>", "").replace("</b>", "")
self.link = link
def __str__(self):
return f"Title: {self.title}\nDescription: {self.description}\nURL: {self.link}\n"
class NaverBlogSearcher:
def __init__(self):
self.client_id = os.getenv("NAVER_CLIENT_ID") # 환경변수에서 Client ID 읽어오기
self.client_secret = os.getenv("NAVER_CLIENT_SECRET") # 환경변수에서 Client Secret 읽어오기
# 환경변수 값이 없을 때 예외 처리
if not self.client_id or not self.client_secret:
raise ValueError("NAVER_CLIENT_ID and NAVER_CLIENT_SECRET must be set as environment variables.")
def get_blog_posts(self, query, display=10):
# 요청 URL 및 헤더 구성
url = f"https://openapi.naver.com/v1/search/blog.json?query={query}&display={display}&sort=date"
headers = {
"X-Naver-Client-Id": self.client_id,
"X-Naver-Client-Secret": self.client_secret,
}
# 네이버 API에 요청 보내기
response = requests.get(url, headers=headers)
if response.status_code == 200:
return self.parse_response(response.json())
else:
print(f"Error: {response.status_code}, {response.text}")
return []
def parse_response(self, data):
# 응답 데이터 파싱
blogs = data.get("items", [])
blog_posts = [BlogPost(blog.get("title"), blog.get("description"), blog.get("link")) for blog in blogs]
return blog_posts
if __name__ == "__main__":
# "동탄" 검색어로 최신 블로그 정보 가져오기
try:
searcher = NaverBlogSearcher()
blog_posts = searcher.get_blog_posts("동탄", 3)
for post in blog_posts:
print(post)
except ValueError as e:
print(e)
환경 변수도 작성했다.
[ .env ]
NAVER_CLIENT_ID=""
NAVER_CLIENT_SECRET=""
3. 실행
dotenvx를 사용해서 실행했다.
> dotenvx run -f .env -- python main.py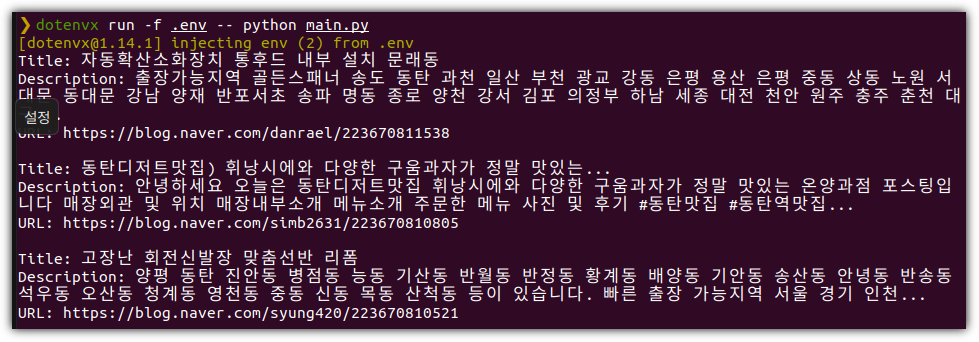
나름 잘 진행되었다 !!! (스스로 뿌듯~)
반응형
'Programming > Python' 카테고리의 다른 글
| 판다스 보다 100배 빠른 불오리들 (FireDucks) (1) | 2024.12.29 |
|---|---|
| 응 아저씨와 함께하는 파이썬 공부 (AI Python for Beginners) (1) | 2024.12.29 |
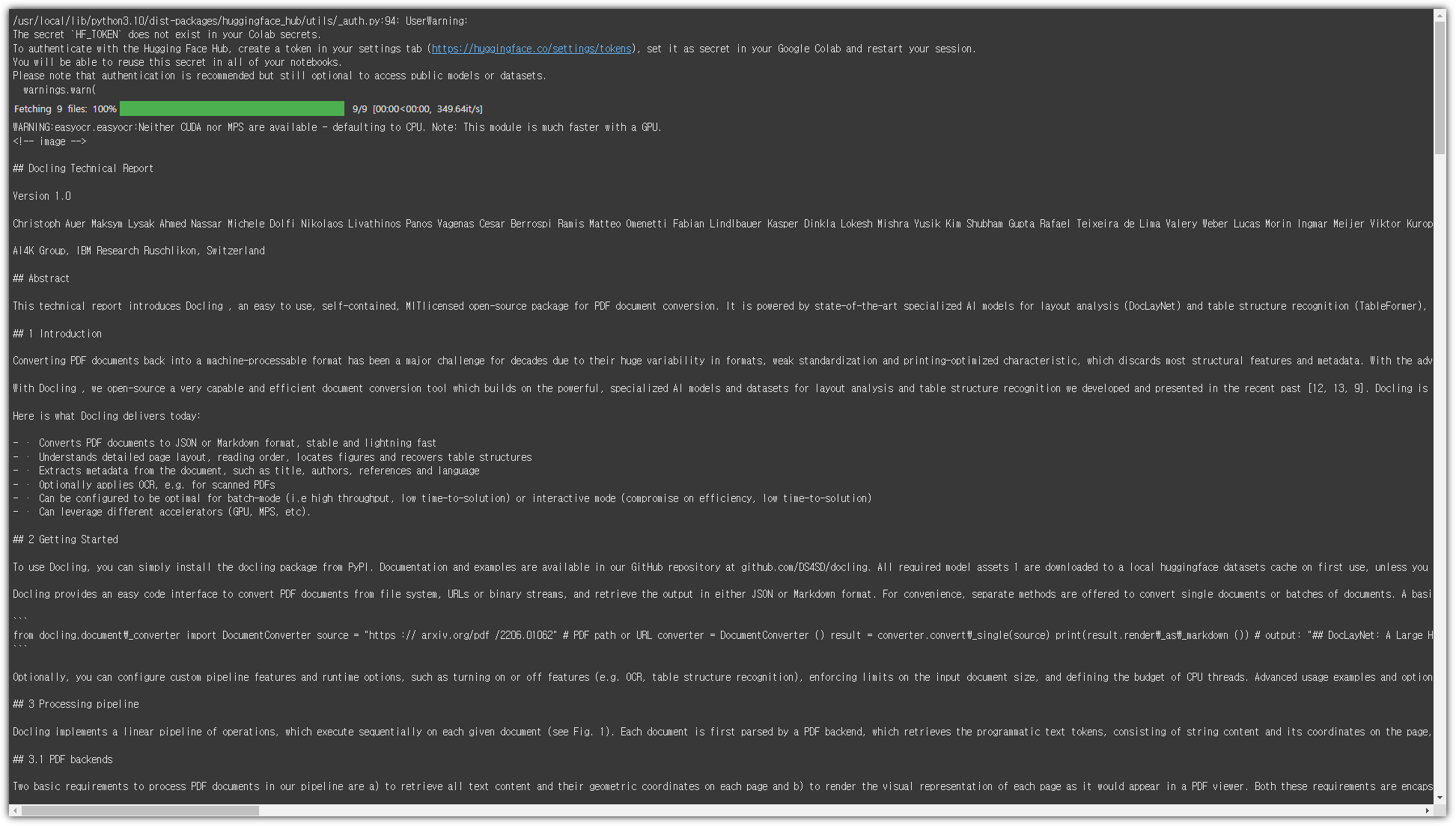
| 문서 파일을 데이터로 만들어주는 Docling (0) | 2024.11.18 |
| FastHTML - 파이썬으로 웹앱 만들기 (0) | 2024.09.23 |
| 날씨 정보 API 활용하기 (Python) (0) | 2024.08.11 |