Local LLM을 직접 띄워서 공부하려는데,
GPU를 갖고 있지 않다고 시작도 하기 전에 포기하는 분들이 의외로 많은 것 같다.
사실 인내심만 충분히 있다면 CPU로도 맛보기는 가능한데도 이를 모르는 경우도 많은 것 같고,
또 하나! 우리의 구글님께서는 아름다운 Colab을 무료로 제공해주고 있기에
이를 이용하면 어지간한 그래픽카드에서도 어려운 모델들을 이용할 수 있게 된다.
[ Gemma ]
이번에 사용해볼 모델은 구글님이 우리에게 은혜를 내려주신 Gemma 이다.
- https://deepmind.google/models/gemma/
구글님이 상업적으로도 사용할 수 있도록 `open-weights`로 공개해준 모델로써,
그다지 많은 인기가 높지는 않지만 구글님이 꾸준히 신경써주셔서 성능도 어지간히 나오는 괜찮은 모델이다.
다양한 유형의 다양한 크기 모델을 제공해주기 때문에, 상황에 맞게 골라서 사용하면 된다.
- https://ai.google.dev/gemma/docs/get_started?hl=ko


다만, 상업용으로도 사용할 수 있는 괜찮은 라이선스 조건이지만
일반적인 라이선스 유형은 아니고 'Gemma License'라는 특화된 라이선스이기에 주의를 하기는 해야 한다.
[ Ollama ]
LLM 모델을 serving하기 위해서는 사실 공부해야할 것도 많고,
vLLM이나 SGLang같은 솔루션들을 살펴보고 이를 실행해야하는 등 어려움이 많다.
하지만, Local LLM을 사용하는 사람들을 위해 은혜로운 솔루션이 등장했으니,
그것이 바로 Ollama이다 !!! 그것도 MIT 라이선스로 !!!

사용법은 더 이상 쉬운 방법이 없을 정도이다.
홈페이지에서의 가이드도 너무나 깔끔하다.
- https://ollama.com/library/gemma3:12b

[ Ollama on Colab ]
Colab에서 GPU 리소스를 사용하도록 하자.
- https://colab.research.google.com/

Ollama 설치를 위해서 기본적인 패키지들을 미리 설치해주자.
| !sudo apt-get install zstd lshw |

Ollama 설치 자체는 너무나 쉽다.
| !curl -fsSL https://ollama.com/install.sh | sh |

서비스 실행은 직접 해줘야 한다.
| !nohup ollama serve > ollama.log 2>&1 & |

실제 실행에는 소요시간이 조금 필요하다. 2~3초 정도!?
여기까지만 하면 기본적인 준비는 끝이다 !!! 너무 쉽지 않은가!?
이제 다양한 활용 방법을 알아보자.
[ Ollama CLI ]
Gemma3 12B 모델을 이용해서 질문을 해보자.
| !ollama run gemma3:12b "한국의 수도는 어디야?" |

잘 대답을 하기는 하는데, 첫 실행에는 3분 정도 소요가 된다.
Gemma3 12B 모델을 다운로드 받는 것에 시간이 걸리는 것이다.
다시 같은 질문을 해보자.
| !ollama run gemma3:12b "동탄이 어디인지 알아?" |

이번에는 13초 정도만에 답변을 해준다.
간단한 Local LLM 사용 ... 정말 쉽지 않은가?!
[ with Python ]
Python으로 LLM을 이용하도록 해보자.
그렇게 하기 위해서는 우선 필요한 Local LLM 다운로드를 먼저 해야한다.
| !ollama list !ollama pull gemma3:12b |

`ollama list`를 이용해서 필요한 모델이 있는지 먼저 확인을 해보고
없으면 pull을 이용해 다운로드를 받으면 된다.
다운로드를 받았다면 이렇게 확인이 된다.

Python을 이용해서 ollama 활용을 하기 위해서는 패키지 설치가 필요하다.
| !pip install ollama |

이제 준비는 모두 끝났다.
코딩을 해보자.
| import ollama try : response = ollama.generate( model= "gemma3:12b" , prompt= "대한민국의 제2의 수도는 어디인가요?" ) print (response[ "response" ]) except Exception as e: print ( f"오류가 발생했습니다: {e} " ) |

순차적으로 문장을 생성하는 LLM 특성을 반영해서
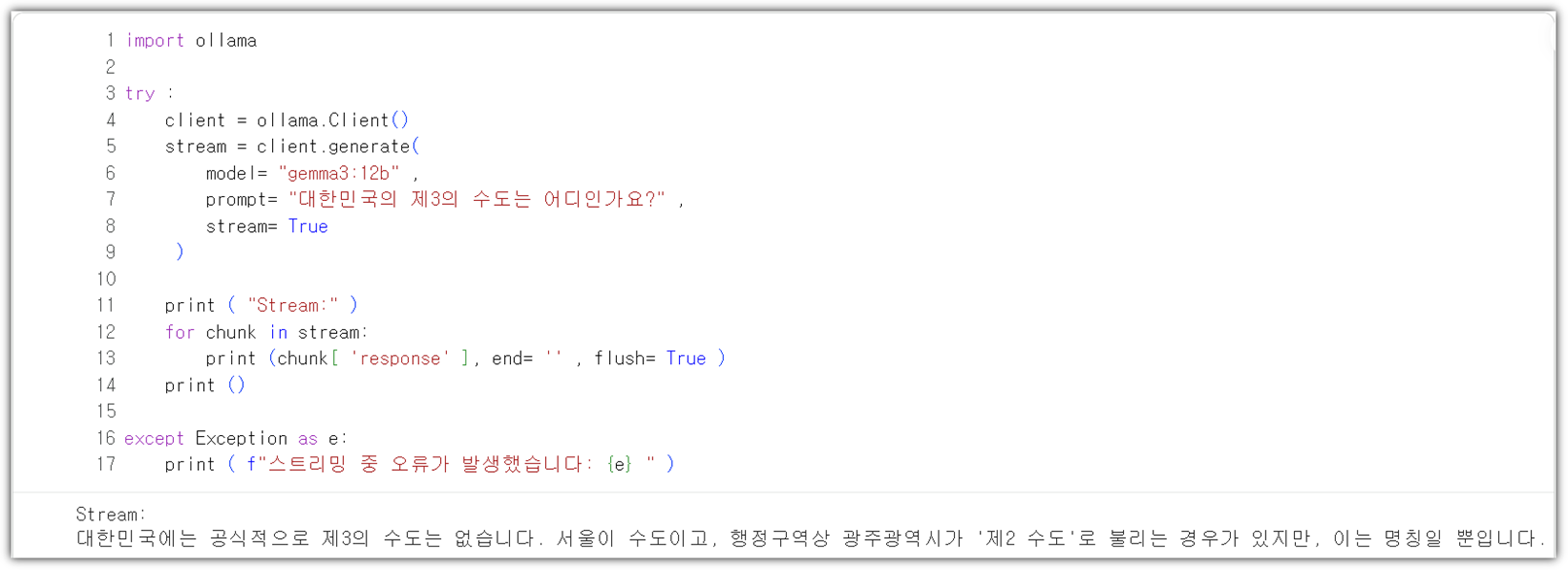
stream 방식으로 처리하도록 해보자.
| import ollama try : client = ollama.Client() stream = client.generate( model= "gemma3:12b" , prompt= "대한민국의 제3의 수도는 어디인가요?" , stream= True ) print ( "Stream:" ) for chunk in stream: print (chunk[ 'response' ], end= '' , flush= True ) print () except Exception as e: print ( f"스트리밍 중 오류가 발생했습니다: {e} " ) |
[ REST API ]
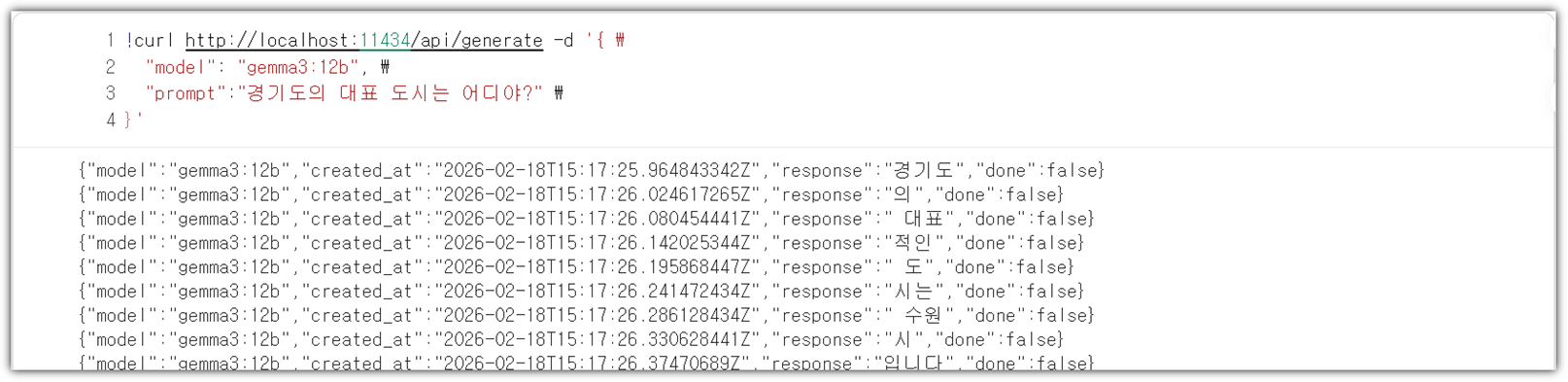
Ollama는 실제로 REST API 방식으로 서빙이 된다.
그렇기에 `curl`을 통해서도 접근을 할 수가 있다.
| !curl http://localhost:11434/api/generate -d '{ \ "model": "gemma3:12b", \ "prompt":"경기도의 대표 도시는 어디야?" \ }' |
generate 방식 말고 chat 방식도 지원을 해준다.
| !curl http://localhost:11434/api/chat -d '{ \ "model": "gemma3:12b", \ "messages": [ \ { "role": "user", "content": "경기도의 대표 도시는?" } \ ] \ }' |

어!? 그렇다면,
Colab으로 서비스를 띄워놓고 내 PC에서 원격으로 사용할 수는 없을까!?
있다!!!! 가능하다!!!
[ ngrok ]
Colab에서 띄워놓은 서비스를 외부에서 접근할 수 있도록 하기 위해서
명시적인 주소를 하나 할당해주는 것이 필요하다.

가입만 하면 무료로 사용할 수 있는 아주 아름다운 서비스이다.
하지만, 당연하게도 token 발급을 해야한다 ^^
- https://dashboard.ngrok.com/get-started/your-authtoken

Colab에 어떻게 설치를 하면 좋을까!?
ngrok은 아주 친절하게 다양한 설치 방법을 제공해준다.
우리는 Download 방식으로 해보겠다.
- https://ngrok.com/download/linux?tab=download
파일을 다운로드 받을 수 있는 주소를 먼저 확보해보자.
이제 Colab에서 설치를 진행하면 된다.
| !wget <URL> !tar -xvzf ngrok-v3-stable-linux-amd64.tgz ngrok !./ngrok config add-authtoken <TOKEN> !ollama serve & ./ngrok http 11434 --host-header="localhost:11434" --log stdout & sleep 5s && ollama run gemma3:12b |

ngrok을 실행하면 URL 주소를 하나 알려준다. 메모하자.

[ Remote Connect with Python ]
집에 있는 내 PC에서 접근해보기 위해서 일단 Python 실행 환경을 확보하자.
최근 유행에 맞춰 `uv`를 이용해 보도록 하겠다.
| > uv init gemma --python 3.12 > cd gemma > uv add langchain_ollama |
소스 코드는 단순하다.
| from langchain_ollama import ChatOllama model = ChatOllama( model="gemma3:12b", temperature=0, base_url="URL" ) response = model.invoke("대한민국의 수도는 어디야?") print(response) |
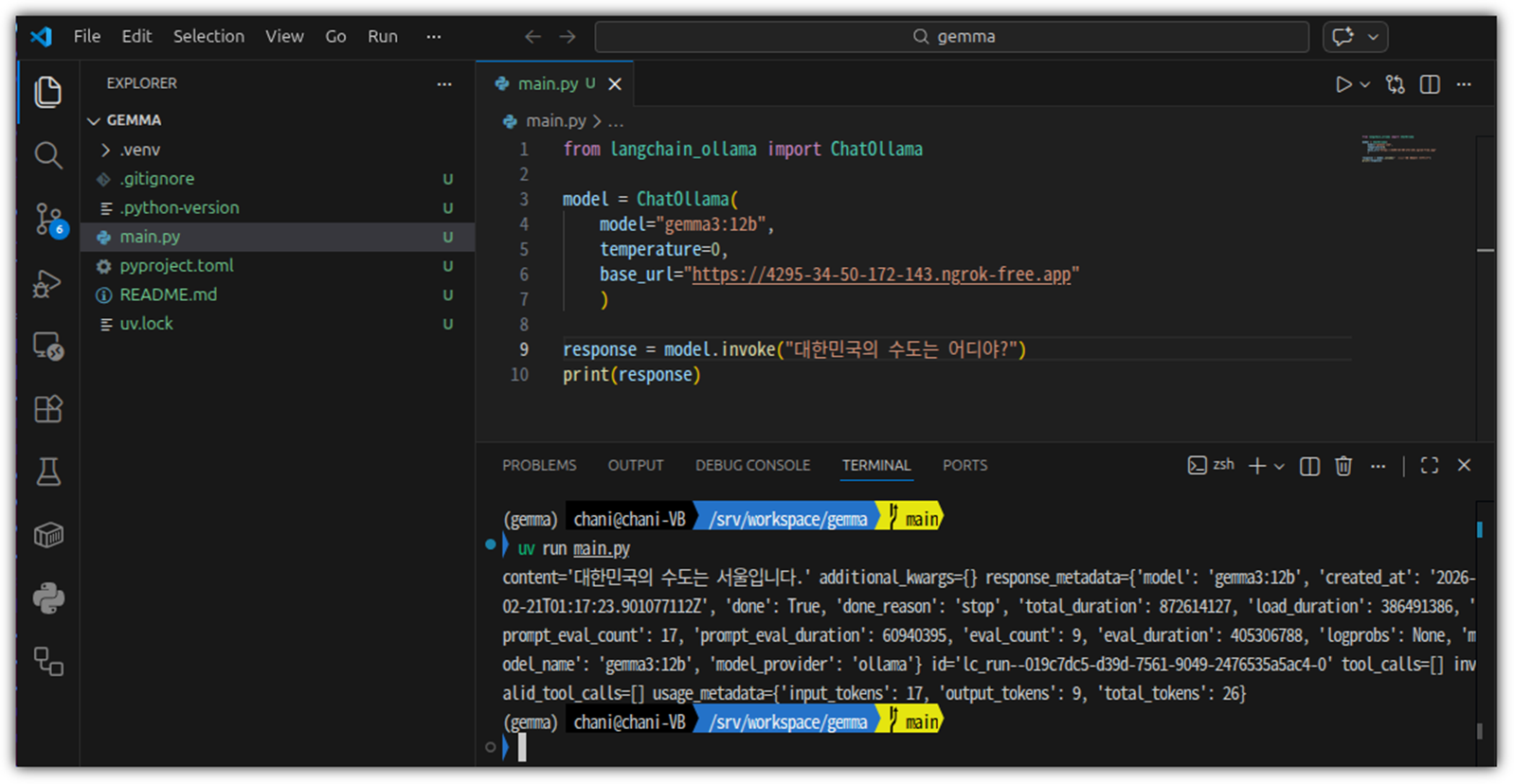
너무나 잘 된다 !!!
이제는 Colab에 나만의 LLM Server를 두고, 마음껏 LLM API를 사용할 수 있게 되었다 !!!
가난한 개발자의 몸부림은 계속 됩니다 !!! ^^
'AI_ML > LLM' 카테고리의 다른 글
| Gemini에게 GitHub PR 코드 리뷰 받기 (0) | 2026.03.21 |
|---|---|
| Gemini API 사용해보기 (1) | 2026.03.15 |
| GitHub MCP Exploited: MCP를 통해 개인 저장소 정보 유출 (0) | 2025.06.03 |
| HuggingFace - LLAMA 3.2 for Korean (2) | 2024.11.12 |
| HuggingFace - Learn - NLP Course #3 (3) | 2024.11.11 |