
▶ 요약
● 데이터 과학 vs 데이터 분석
- 데이터 분석은 데이터 과학에 포함되는 one of them
- 데이터 과학 = 데이터 분석 + 머신 러닝
● '데이터 분석'의 정의
- 광의적 정의 : 데이터 수집/처리/정제 및 모델링을 포함한 전체 영역
- 협의적 정의 : 기술통계, 탐색적 데이터 분석, 가설 검정
● 이번 공부에서 사용하는 Python Package
- Numpy
- pandas
- matplotlib
- SciPy
- scikit-learn
● 데이터 파일 확보하기
- 이번 공부에서는 '도서관별로 공개된 장서/대출 데이터'를 사용
. https://www.data4library.kr/openDataL
- 한글 데이터의 경우에는 특히 인코딩에 대한 처리가 필요할 수 있음
● pandas dataframe
- 하나의 행은 여러 데이터 타입의 열을 갖을 수 있다.
- 하나의 열은 한 종류의 데이터타입으로만 구성된다.
▶ 기본 미션
p. 81의 확인 문제 4번 풀고 인증하기
4. 판다스 read_csv() 함수의 매개변수 설명이 옳은 것은 무엇인가요?
① header 매개변수의 기본값은 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다.
② names 매개변수에 행 이름을 리스트로 지정할 수 있습니다.
③ encoding 매개변수에 CSV 파일의 인코딩 방식을 지정할 수 있습니다.
④ dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다.
매뉴얼을 찾아보자.
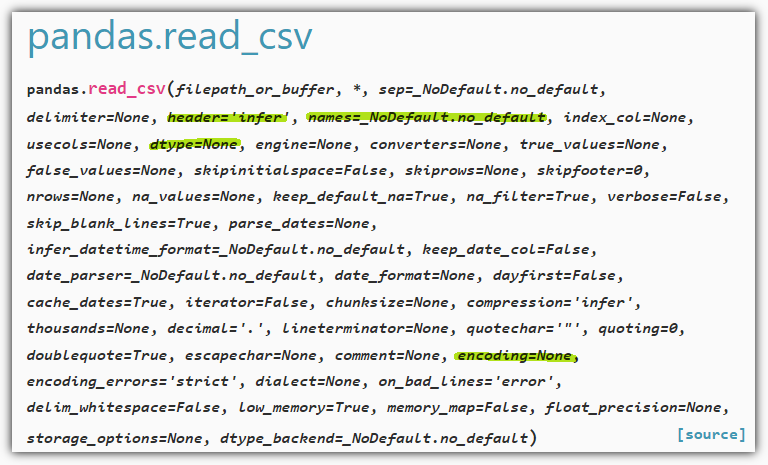
① header 매개변수의 기본값은 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다. (X)
header 매개변수의 기본값은 "infer"이고, 자동으로 header를 추론하게 된다.
header가 없는 경우 "None"으로 명시해줘야 한다.

② names 매개변수에 행 이름을 리스트로 지정할 수 있습니다. (X)
names 매개변수는 column 이름을 지정하기 위한 것이다.

③ encoding 매개변수에 CSV 파일의 인코딩 방식을 지정할 수 있습니다. (O)

④ dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다.
전체 dataset의 데이터 타입을 지정할 수도 있지만, 개별 column의 데이터 타입을 지정할 수도 있다.

▶ 선택 미션
p. 71 ~ 73 남산 도서관 데이터를 코랩에서 데이터프레임으로 출력하고 화면 캡처하기
→ 다음 순서대로 진행해보겠다.
① 도서관 데이터 다운로드 받기
② 구글 드라이브에 업로드 하기
③ Colab 실행해서 코드 작성하기
차근 차근 진행해보자.
① 도서관 데이터 다운로드 받기
- https://www.data4library.kr/
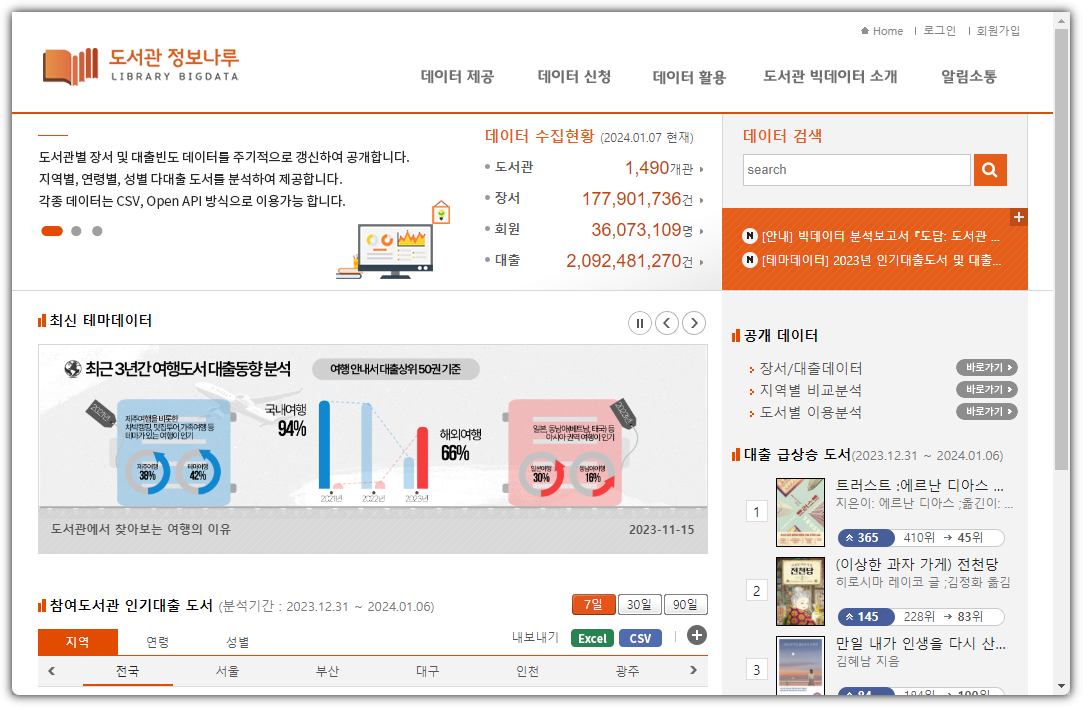
상단 탭 메뉴에서 "데이터 제공"을 선택하고 받고자 하는 도서관을 선택해보자.
나는 ... 우리 동네 도서관을 골라봤다 ^^

"도서관명"을 클릭하면 상세 화면이 나온다.
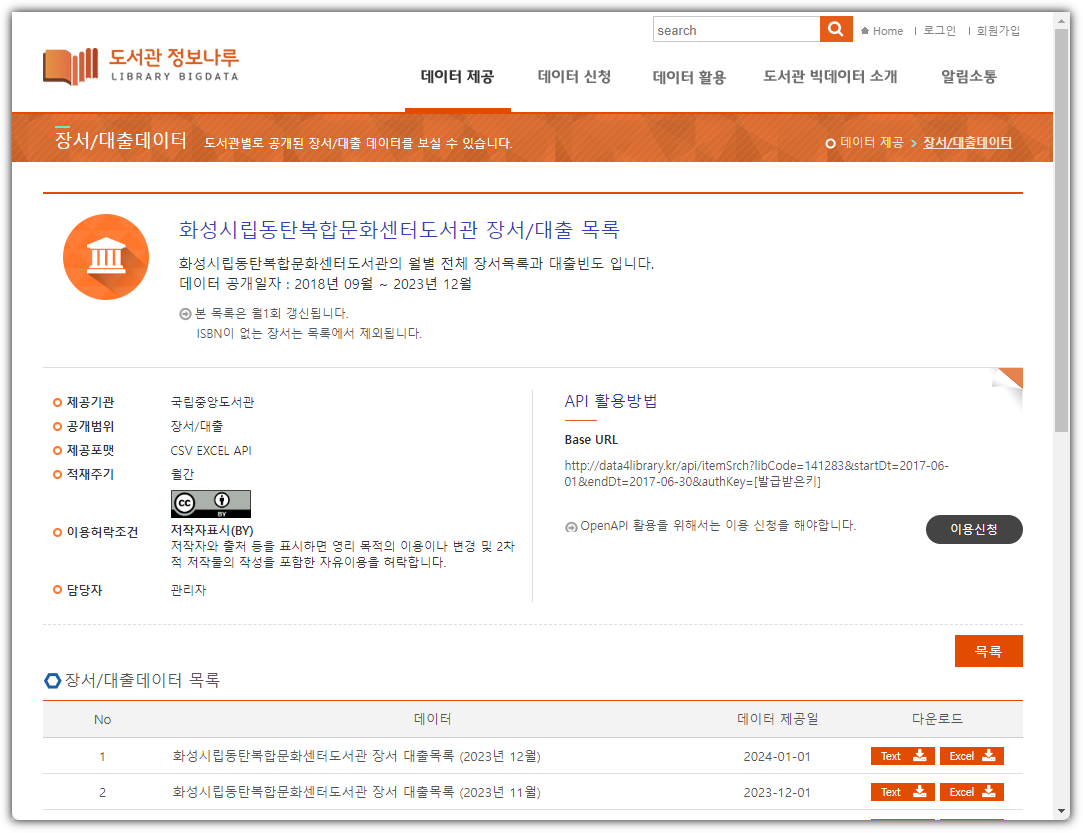
하단에 있는 리스트 중에서 마음에 드는 것을 하나 고르고,
다운로드에서 "Text"를 선택하면 CSV 파일을 다운로드 받을 수 있다.
② 구글 드라이브에 업로드 하기
구글 드라이브에 들어가서 이번 공부에서 사용할 폴더를 하나 새로 만들자.
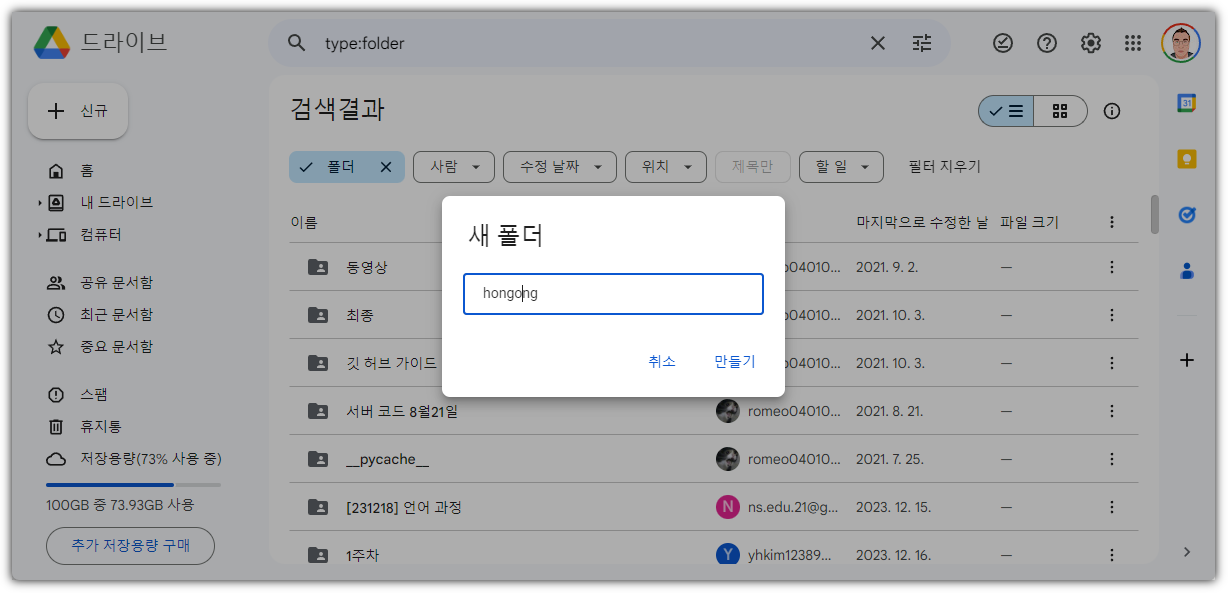
앞에서 다운로드 받은 파일을 업로드 하자.

③ Colab 실행해서 코드 작성하기
이번 공부를 위한 새 노트를 하나 만들자.
교재를 보면 'gdown' 패키지를 통해서 구글 드라이브에 있는 파일을 다운로드 받을 수 있다고 하는데,
내가 멍청해서인지.... 성공하지 못했다.
이유는 아마도 인증 관련해서 처리가 안되어서인 것 같은데,
구글 드라이브에 있는 파일을 누구나 다운로드 받을 수 있도록(인증 없이 다운로드 되도록)
권한을 처리해주면 될 것 같기는 하지만.... 여하튼, 그냥 사용하기에는 이슈가 있었다.
하지만, 우리의 Colab은 구글 드라이브를 편하게 사용할 수 있도록 기능을 제공해준다!!!

왼쪽 위의 저 메뉴를 누르면 된다.
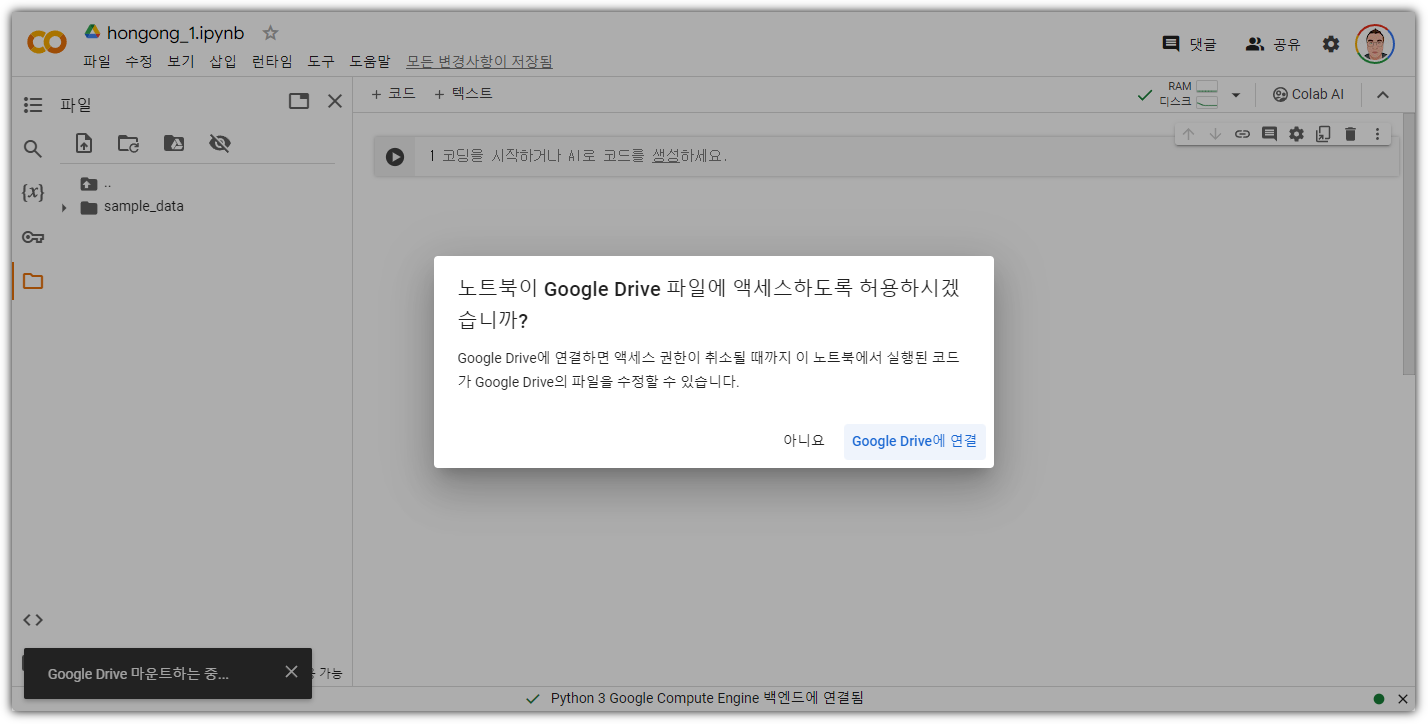
Google Drive 연결을 진행하면 된다.

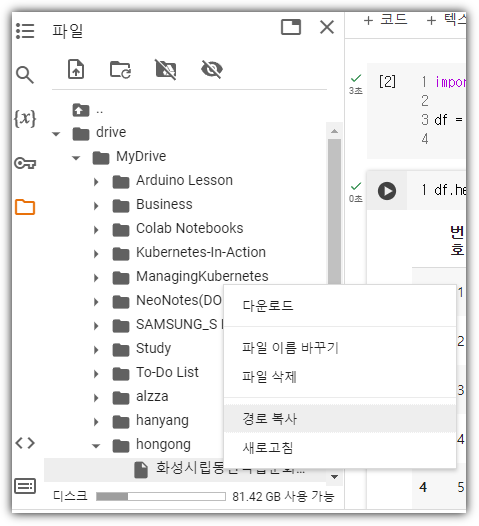
drive라는 폴더에 Google Drive가 마운트 되어있는 것을 확인할 수 있다.
우리는 이제 그냥 사용하면 된다.
파일 경로를 일일이 타이핑하려면 힘드니까 편하게 복사하자.
이번 숙제의 소스코드는 정말 심플하다.
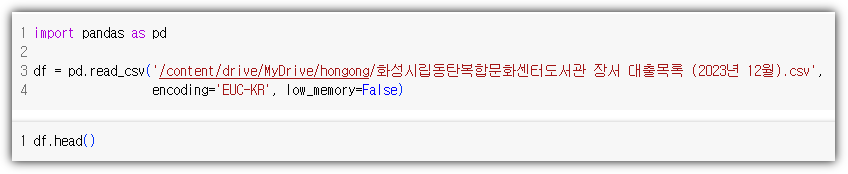
실행 결과는 다음과 같다.
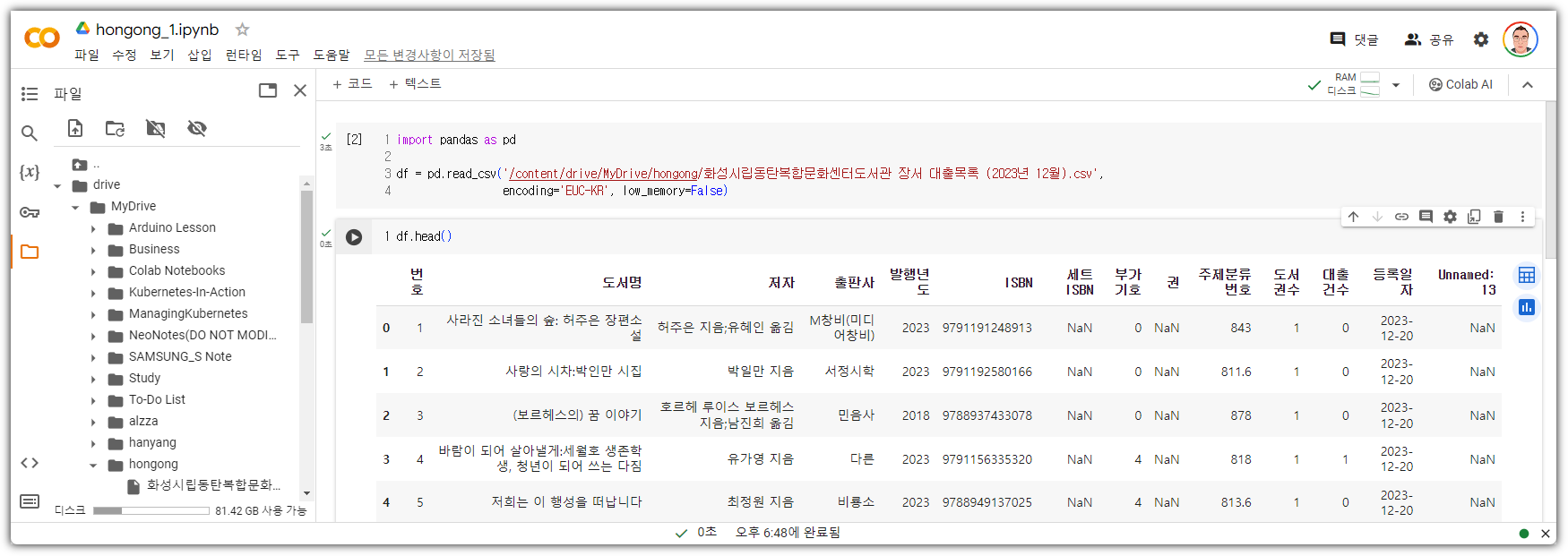
이번 공부는 여기까지~
'Books' 카테고리의 다른 글
| [혼공데분] 3주차_데이터 정제하기 (1) | 2024.01.21 |
|---|---|
| [혼공데분] 2주차_데이터 수집하기 (2) | 2024.01.16 |
| [혼공학습단 11기] 혼자 공부하는 데이터 분석 with 파이썬 (0) | 2023.12.27 |
| [디코딩] 챗GPT 개발자 핸드북 (0) | 2023.08.28 |
| [정보문화사] 파이썬과 엑셀로 시작하는 딥러닝 (0) | 2023.08.01 |