최근 AI 에이전트를 이용하여 코딩 작업을 하면서
병렬로 동시에 여러 작업을 하는 경우에 유용한 기능으로 git worktree가 각광을 받고 있다.
git worktree가 어떤 기능을 제공해주는지
어떤 상황에서 필요로 하는지에 대해서 알아보고자 한다.
[ 준비 ]
실습을 해보기 위해서 저장소 하나를 clone 받아서 준비해보자.

[ 문제 상황 ]
feature-1 작업을 수행하기 위해 브랜치(branch)를 하나 생성해서 새로운 파일을 하나 만들었다고 해보자.
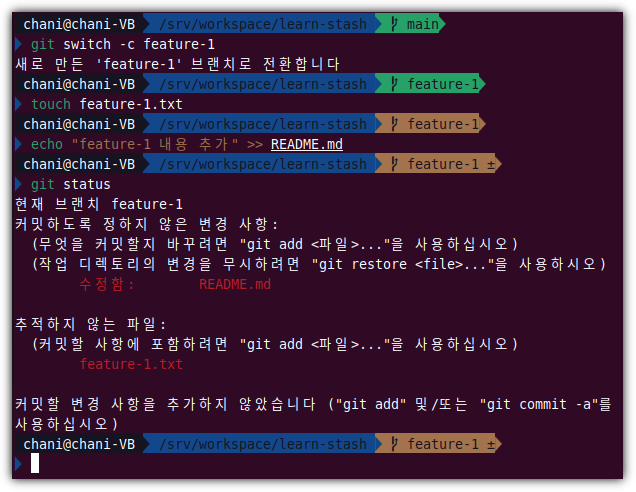
그런데, 갑자기 급하게 보안 이슈가 발생하여 hotfix 작업을 해야한다고 해보자.
feature-1 작업은 아직 진행 중이기에 commit까지 할 상황은 아니지만
지금까지 작업한 내용은 계속 보관을 하고 싶다고 하면 어떻게 해야할까?
[ 솔루션 #1 - new branch ]
그냥 다른 브랜치(branch)로 이동하면 되는 것 아닐까?

잠시 main 브랜치로 이동을 해보면 알겠지만,
feature-1 브랜치에서 작업하던 내용이 그대로 딸려온다.
여기에서 hot-fix-1 브랜치를 새로만들어도 마찬가지이다.
즉, 전에 작업하던 것을 잠시 치워놓고 다른 일을 할 수 있는 상황은 아니라는 것이다.
[ 솔루션 #2 - stash ]
이럴 때 가장 먼저 생각나는 방법은 `git stash` 명령어일 것이다(git 공부를 했다면 '이어야 한다'! ^^).
임시 보관이라는 말이 딱 어울리는 명령어이다.

변경 사항들을 모두 stash 명령어를 통해 따로 저장해놓으면,
현재 working directory는 깨끗해지게 된다.
`-u` 옵션은 추적하지 않는(untracked) 파일도 모두 stash 저장하라는 것이고,
`-m` 옵션은 stash 저장할 때 메모를 하도록 하기 위해 사용하는 것이다(여러 stash 저장 목록 구분을 위해).
이제 급한 hot-fix 업무를 처리한 후에
다시 돌아와서 전에 작업하던 내역을 불러와 계속 이어서 작업을 하면 되는 것이다.

그런데,
이렇게 좋은 stash 기능도 원하는 상황에 따라서는 충분하지 않을 수도 있다.
[ `새로운` 문제 상황 ]
`git stash` 기능이 정말 유용하긴 하지만,
만약 한 번에 하나의 작업이 아니라 동시에 여러 작업을 해야 한다고 하면 어떻게 해야할까?
앞서 말한 AI 에이전트가 동시에 여러 기능을 개발하도록 하고 싶은 경우,
여러 디렉토리에 각각 git clone 받아서 개발하도록 하면 될까?
그런데, 서로 개발 중인 내용을 주고 받는 것도 해야한다고 하면?
`stash`가 아니라 새로운 기능이 필요하다 !!!
[ 솔루션 #3 - worktree ]
현재 상태를 먼저 점검해보고, worktree를 사용해보자.

feature-1 브랜치에서 기존 파일 수정도 하고, 새로운 파일을 생성도 하던 중
긴급히 hot-fix를 진행해야 하는 상황에서 worktree를 사용하면 된다.

'git worktree add {디렉토리 경로} -b {새 브랜치 이름}` 형태로 사용하면 된다.
지정한 디렉토리 경로에 새로운 작업 공간을 마련하게 되기에
현재 디렉터리 하위 보다는 상위 경로로 지정해주는 것을 권장한다.
기존 branch를 사용할 때에는 `-b` 옵션을 사용하지 않아도 되지만
새로운 branch를 생성하도록 할 때에 `-b` 옵션을 사용하면 된다.
그런데, 여러 디렉토리에 각각 clone 받은 것과 어떤 차이가 있을까?
아래 예시를 자세히 살펴보자.
worktree로 생성된 hot-fix-1 작업 공간에서 새로운 작업을 하고 commit까지 했다.
`git log`를 통해서 당연히 새로운 commit까지 이력이 확인 된다.
그런데, 기존 디렉토리로 돌아가서 `git log`를 했는데 새로운 이력이 여기에서도 그대로 나온다.

그렇다!
worktree로 연결되어 있는 작업 공간끼리는 서로 공유 된다.
`git stash`로 잠시 저장해 놓은 이력들도 서로 공유하면서 이용할 수 있다.
삭제는 `git worktree remove {경로}` 명령어를 사용하면 된다.

AI 에이전트에서 이를 어떻게 활용하면 좋을지에 대해서는
각 AI 에이전트에 대해서 실습하면서 공부해보도록 하겠다.
'SCM > Git-GitHub' 카테고리의 다른 글
| 실용적인 코드 리뷰 문화 엿보기 (feat. 뱅크샐러드) (1) | 2026.04.04 |
|---|---|
| Branch protection rules (코드리뷰를 필수로 설정하기) (1) | 2026.03.14 |
| 저장소 이름 바꾸기 (Rename Repository) in GitHub (0) | 2026.02.07 |
| 저장소 삭제 (Delete Repository) in GitHub (0) | 2026.02.07 |
| 저장소 생성 (Create Repository) in GitHub (0) | 2026.02.07 |