『행복한 프로그래밍 : 컴퓨터 프로그래밍 미학 오디세이』의 다음 책으로 『행복한 프로그래밍』에서는 전문적이고 기술적인 내용보다는 일반적인 독자들까지 고려한 가벼운 내용을 주로 다루었다. 이번 책 『누워서 읽는 알고리즘』은 기술적인 깊이가 (저자의 표현에 의하면) '반걸음' 정도 다가간 시도로 실전 프로그래밍을 업으로 하는 사람들과 하는 편안하고 즐거운 알고리즘에 관한 '수다'를 담고 있다. 이 책에 등장하는 알고리즘은 일반적인 알고리즘 교과서에서 흔히 볼 수 있는 정렬(sort), 검색(search), 이진트리(binary tree), 리스트(list), 퇴각 검색(backtracking), 해시(hash), 유클리드(Euclid) 알고리즘, 동적 프로그래밍 (dynamic programming) 등과 같이 익숙한 것과 팰린드롬(palindrome), 둠스데이(doomsday), 사운덱스(soundex), 메르센느 소수(mersenne prime) 처럼 많이 알려지지 않은 것으로 이루어져 있다. 1장과 2장은 이러한 알고리즘으로 가볍게 수다를 떨고, 3장과 4장은 다른프로그래머가 작성한코드를 함께 감상해 볼 수 있도록 구성되어 있다.
이 책은 딱딱한 알고리즘 이론서가 아니다. 오히려 맛있는 읽을 거리를 만들기 위해서 알고리즘과 같은 기술적인 내용을 ‘동원한’ 책이다. 실전 프로그래밍을 업으로 삼고 있는 독자와 함께 가볍게 ‘수다’를 떨면서 우리가 매일 수행하는 ‘일’이 얼마나 재미있는지, 얼마나 아름다운지 그리고 얼마나 창조적인지, 또 문제를 해결해야 하는 상황에 처했을 때 해결 능력을 길러주기 위한 지침서이다.
현실세계와 유사한 재미있는 퀴즈 문제로 독자의 흥미를 유도하기도 하고 때로는 딱딱한 수학 문제로 긴장감을 고조시킨다. 지저분한 펄 코드가 등장하기도 하며 깔끔하고 읽기 쉬운 C 코드 또한 자주 등장한다. 정렬이나 탐색 리스트 등의 정통 알고리즘도 책의 곳곳에 녹여 부었다. 책을 읽는 도중 삽화나 특이한 그림을 보는 재미 또한 쏠쏠하다는 점도 이 책의 부수적인 장점이다.
저자 : 임백준
현재 미국 루슨트 테크놀로지스의 네트워크 운용 소프트웨어 그룹에서 소프트웨어 설계자로 일하고 있다. 한빛미디어와 함께 다수의 컴퓨터 서적을 번역했고, 2003년 5월에는 『행복한 프로그래밍: 컴퓨터 프로그래밍 미학 오디세이』(한빛미디어, 2003)를 출간했다. 인터넷 신문 「프레시안」 외 여러 매체에 칼럼을 기고하고 있다.
목차
머리말
1장. 재즈로 여는 아침의 향기
01. 누워서 읽는 알고리즘
02. 퍼즐로 풀어 보는 알고리즘의 세계
03. 데이터 구조 정의하기
04. P를 출력하는 프로그램 P
05. 숨어 있는 버그를 찾아라
06. 톡톡 튀는 알고리즘 만들기
07. 팰린드롬의 세계
08. 콘웨이의 둠스데이 알고리즘
2장. 록과 함께 하는 정오의 활기
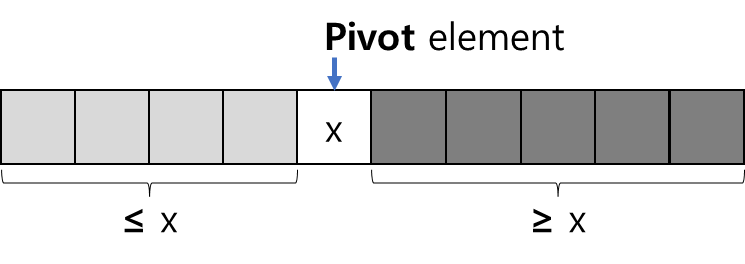
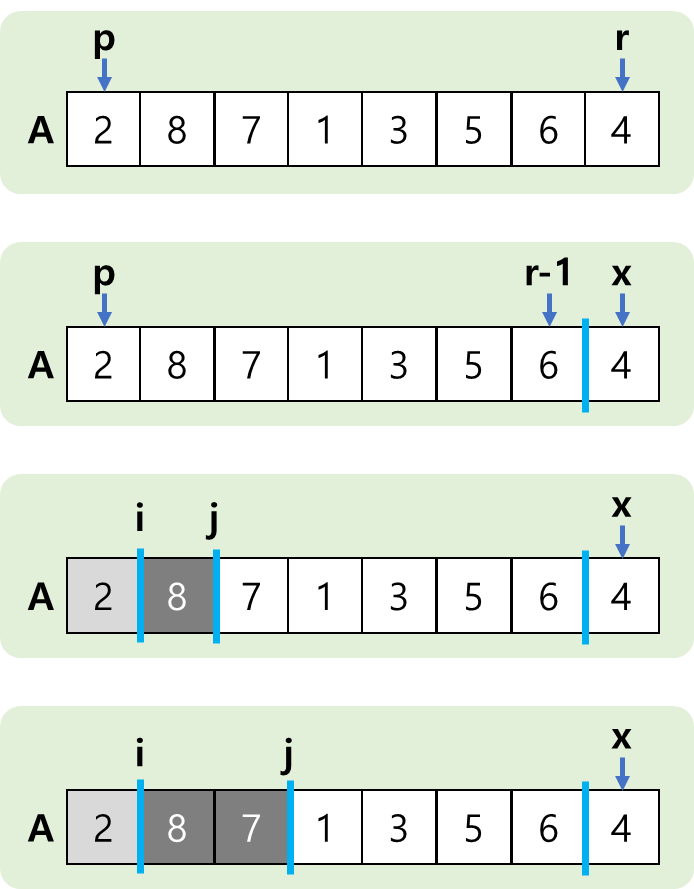
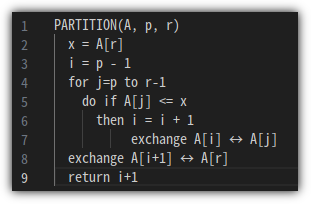
01. 정렬 알고리즘
02. 검색 알고리즘과 최적화 문제
03. 동적 프로그래밍
04. 해시 알고리즘
05. 사운덱스 검색 알고리즘
06. 수도사 메르센느
07. 프로그래머가 느끼는 성취감의 본질
08. 문학적 프로그래밍
3장. 하드코어로 달아오르는 뜨거운 오후
01. 유클리드 알고리즘
02. 재귀의 마술
03. 리베스트, 샤미르, 에이들맨의 수학 게임
04. RSA 알고리즘
05. 잠깐 쉬어 가기
06. RSA 알고리즘 - 계속
07. 세 줄짜리 펄 프로그램
08. 해커들이 작성한 시(詩) 이해하기
09. 두 줄짜리 RSA 알고리즘
4장. 클래식으로 마무리하는 차분한 저녁
01. N개의 여왕 문제
02. 눈으로 풀어 보는 N개의 여왕 문제
03. 문제 속에 숨어 있는 단편적인 알고리즘
04. 재귀와 스택
05. 제프 소머즈의 알고리즘
06. 비트 연산자 복습하기
07. 2의 보수
08. 제프 소머즈 알고리즘 분석
참고 문헌 및 웹사이트
이 책에서 소개한 알고리즘
# 2007.06 ~ 2007.07
정말 재미있게 읽은 책이다. 딱, 내가 원하는 그런 내용들이었고, 딱 내가 원하는 수준의 내용이어서 너무나 마음에 든 책이다. 이 책을 읽고선 나머지 '임백준'씨의 책들을 전부 사서 읽었다. 이 책을 읽고는 감동은 아니어도 공부에 대한 자극은 충분히 받았다.
최근에 '뉴욕의 프로그래머'라는 책이 나왔던데... 그 책을 사서 보려다보니 다시 이 책이 떠올라서 이렇게 브로그에 흔적을 남긴다.
음, 얼마 후면 이 책의 내용을 다시 한 번 써먹을 일이 생길 것 같아서 역시나 이 책을 다시 한 번 봐야할 것 같다.