사실 개인적으로 NumPy 공부가 처음이 아니기에,
너무 기본적인 부분은 skip 하고 계속 기억하면 좋을만한 것들만 추려서 포스팅하겠다.
1. Environment
뭔가 차별점을 두기 위해 실습 환경을 다음과 같이 정해서 진행해보겠다.
- Ubuntu 20.04
- Miniconda + conda-forge
- Jupyter Notebook
혹시 모를 저와 같은 삐딱한 마음을 먹으신 분들이 계시면, 아래 링크를 참고하세요 ^^
- 회사에서 Anaconda 사용하기 (Miniconda + conda-forge)
conda를 이용하여 가상환경을 생성하고,

Jupyter Notebook 패키지들을 설치하고,
Jupyter Notebook을 실행하면 된다.

그러면 아래와 같이 예쁜 웹 페이지가 짜잔~

실제 잘 동작하는지까지만 조금 더 살펴보자.
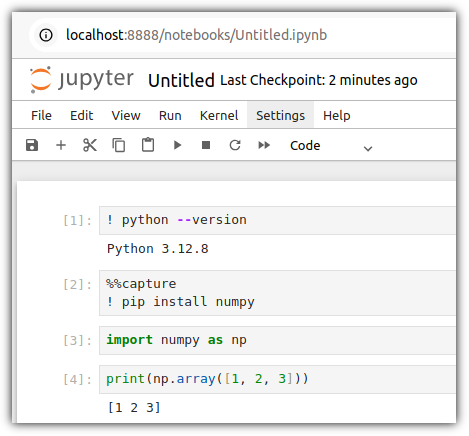
Local 환경에서는 기본적으로 numpy 라이브러리도 설치가 안되어 있기에 필요하다면 설치를 해줘야 한다.
이런 불편함(?)이 앞으로 종종 발생하겠지만, 바로 이런 부분이 know-how 이자, 역량이라고 믿는다! 😁
2. Axis
매번 방향이 헷갈려서 일단 값 넣어보고, 결과 확인 후 '어? 이게 아닌가?'하는 ... 그 악명 높은 axis !!!

왜 axis 위치가 자꾸 변하는걸까?
아래 코드를 잘 살펴보자.

shape에서 나오는 순서대로 번호가 매겨진다고 생각하면 될 것 같다.
책에서는 다음과 같이 설명해주고 있다.
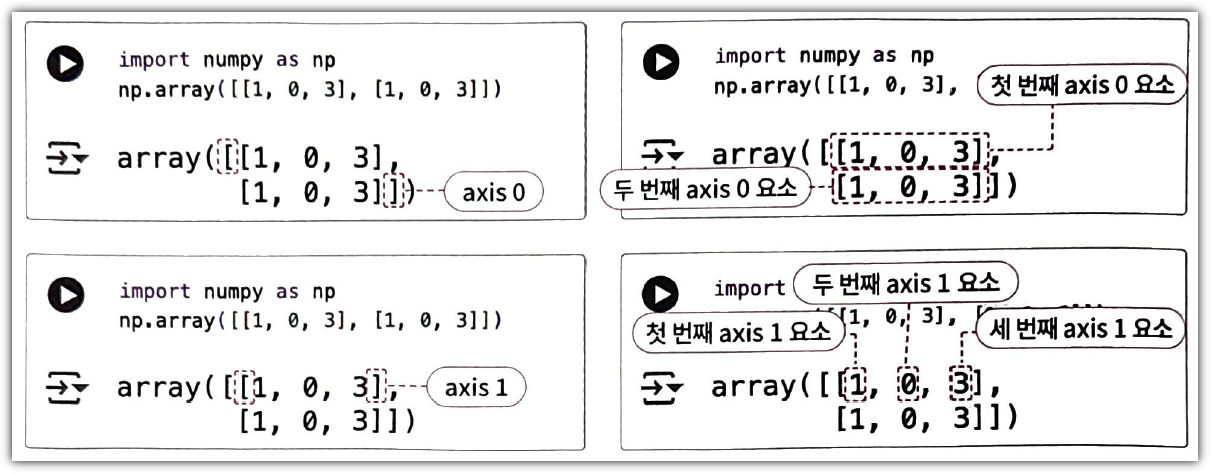
같은 이야기를 하고 있으니 각자 편한 방법으로 기억하면 되겠다.
3. Data Type
사실 그리 신경을 쓰지 않았던 부분이긴 한데,
이번에 데이터 타입 코드에 대해 새롭게 알게 되어서 좋았다! (비트와 바이트를 넘나드는 표기법 왠지 싫다!)

코드를 이용해서 확인해보면 다음과 같다.

기본값으로 64비트 = 8바이트나 사용하다니! 이런 부르주아 같은 넘파이 !!!
4. Make ndarray
리스트나 튜플로부터 넘파이 배열을 만드는 것은 아래 내용 참고해보면 된다.

일련의 데이터 생성과 함께 차원을 변경하는 것까지 살펴보면 다음과 같다.

이번에는 0부터 100까지의 임의의 숫자로 3차원 넘파이 배열을 만드는 것을 살펴보자.

수학의 기본은 0과 1이다 😁
원하는 차원만 입력해주면 된다.

5. Operations
이제 본격적으로 연산에 대해서 알아보자.

행렬에서의 사칙연산은 같은 위치끼리의 연산으로 이루어진다.
위의 예시를 꼼꼼하게 살펴보기 바란다.
하지만, 행렬 연산의 꽃은 사칙 연산이 아니라 "행렬 곱셈"이다.
영어로는 'Matrix Multiply"이지만, 약자인 "matmul"로 더 많이 불리운다.
연산 기호로는 "@"가 쓰인다.

우리의 colorful한 책에서는 다음과 같이 친절하게 연산 과정을 설명해준다!
이 그림 하나면 끝이다!!! 😍

의외로 종종 사용하게 되는 비교 연산도 할 수 있다.

6. Functions
넘파이가 기본적으로 제공해주는 다양한 함수들이 있다.

넘파이 함수에 배열을 넣어주는 방법 말고,
넘파이 배열에서 바로 함수를 호출하는 방법도 있다.

그런데, 모든 함수가 이렇게 되는 것은 아닌 것 같다.
조심해서 사용해야 할 것 같다.

많이 사용하는 집계 함수들에 대해서도 알아보자.

함수의 파라미터로 axis를 넣으면 원하는 방향으로의 값을 계산할 수도 있다.

7. Indexing and Slicing
넘파이 배열의 특정 위치에 있는 값을 확인하고 싶다면? 인덱싱을 이용하면 된다!

처음에 이런 사용법을 봤을 때 깜짝 놀랐다. ","를 사용하다니????
자고로 배열이라면 "[ ]"을 이용해야지 !!!
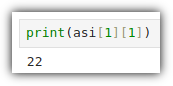
그렇다! 배열처럼 사용할 수도 있다.
하지만, 넘파이에서 다루는 데이터 타입을 배열이라 생각하지 말고,
"행렬"이라고 생각을 하면서 ","를 사용하는 것을 기준으로 삼아야 할 것이다 😎
이번에는 slicing에 대해서 살펴보자.

"asi[0, 0:2]"에 대해서 말로 설명을 해보면,
"0 행에 있는 0부터 2 이전까지(1까지)의 컬럼에 있는 값으로 이루어진 행렬(배열)"이다.
"맨 처음부터" 또는 "맨 끝까지"와 같은 표현도 가능하다.

아무것도 명시하지 않으면 all의 의미를 갖는다.
8. Boolean Indexing
넘파이 행렬에 특정 조건에 맞는지 여부를 확인하려면 다음과 같이 할 수 있다.
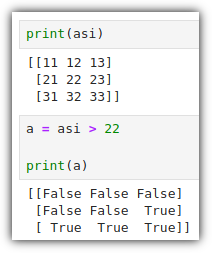
행렬 크기는 유지하면서 Boolen 값으로 채워지게 된다.
이것을 이용하면 다음과 같이 할 수 있다.

특정 조건에 맞는 값만 채워져있는 새로운 행렬(배열)이 만들어진다.
당연한 이야기이지만, 조건을 굳이 변수에 담지 않고 바로 사용할 수도 있다.
단순히 출력에만 이용할 것이 아니라 값 변경에도 활용할 수 있다.

9. Integer Array Indexing
특정 행렬(배열)에 있는 값들을 이용해서 다른 행렬을 만들고자 할 때 사용할 수 있는 방법이다.

다차원 형태로 만들 수도 있다.

10. reshape
ML이나 DS에서도 많으 쓰이지만, 특히 DL에서 많이 사용되는 reshape 😍 행렬(배열)의 형태 바꾸기 !!!

당연한 것이지만, 요소 개수가 맞아 떨어져야 한다.
만약 안맞으면?

에러를 밷어낸다 😅
특이한 파라미터 "-1"은 일종의 "auto"라고 보면 될 것 같다.

정해진 값을 기준으로 알아서 값을 맞춰준다.
reshape() 함수의 사촌인 resize() 함수도 있다.

reshape()은 원본을 직접 수정하지 않고, resize()는 원본 자체를 변경한다.
DL 공부할 때 많이 사용하는 평탄화(flatten)를 해보자.

실제로는 reshape(-1)을 많이 사용하는 것 같다.
11. Transpose
행과 열을 바꾸는 전치(transpose)에 대해서 살펴보자.

두 행렬을 행렬곱 하면 어떻게 될까?

첫번째 행렬의 행의 개수와 두번째 행렬의 열의 개수가 맞지 않아 행렬곱을 할 수가 없다.
앞 또는 뒤에 있는 행렬을 전치해줘야 한다.

원본 값을 수정하지는 않는다. 원본 자체를 바꾸고 싶으면 "bt = bt.T" 와 같이 사용해야 한다.
12. stack / split
행렬을 합치는 것이 stack, 분할하는 것이 split이다.
행렬을 합칠 때에는 수평(horizontal) 방향으로 합칠 것인지,
수직(vertical) 방향으로 합칠 것인지 정해서 해야 한다.
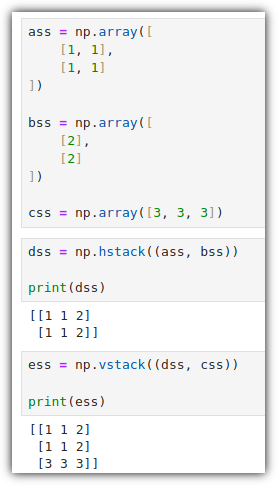
분할도 방식은 똑같은데, 몇 조각으로 쪼갤 것인지만 추가해주면 된다.

*stack 계열과 마찬가지로 사용할 수 있는 것이 conatenate() 함수도 있다.

axis 값을 이용해서 방향을 지정할 수가 있다.
그런데, 아래와 같은 에러를 만날 수 있다.

어!? 아까 vstack()은 잘 되었는데!? 왜 에러가!?

css 행렬을 경우 1차원이기 때문이다.
같은 차원끼리만 concatenate()를 할 수가 있다.
그래서 같은 차원으로 만들어서 진행하면 된다.
*split() 함수의 경우 행렬을 나눠주는 것인데,
마지막 2개의 행만 뽑아오고 싶거나 하면 어떻게 해야할까?
그런 경우에는 slicing을 이용하면 될 것 같다.
우와아아.... 정말 길다.
연습문제까지 포함하면 총 88페이지까지의 분량이다.
연습문제는 나중을 위해 아껴 두겠다. (절대 퓌곤해서가 아니다! 정말! 정말이라구!)
'Books' 카테고리의 다른 글
| [파이썬 데이터 분석가 되기] 03 - Matplotlib (0) | 2025.02.01 |
|---|---|
| [파이썬 데이터 분석가 되기] 02 - Pandas (0) | 2025.01.25 |
| [파이썬 데이터 분석가 되기] 00 - 공부 시작 (0) | 2025.01.15 |
| [혼공머신] 6주차 - CH.07 딥러닝을 시작합니다 (3) | 2024.08.25 |
| [혼공머신] 5주차 - CH.06 비지도 학습 (0) | 2024.08.16 |







