안드레 카파시(Andrej Karpathy)와 더불어
초보 병아리들을 위한 강의에 정말 진심인 또 한 명의 명장, 앤드류 응(Andrew Ng) 아저씨 !!!
이번에는 파이썬 그것도 그냥 파이썬이 아니라 AI 파이썬 강의를 가지고 찾아오셨다.
- https://www.deeplearning.ai/short-courses/ai-python-for-beginners/

살짝 아쉬운 점은 한국어 더빙 또는 한글 자막이 있으면 좋았겠지만,
영어 자막 정도로 만족해야 한다. (훌륭한 무료 강의인데, 이것만으로도 감지덕지!)

출석부 도장 쾅!

동영상 녹화 강의 단점을 해소하기 위한 AI Chatbot을 제공해준다.
아쉽게도 한글은 안되고 영어로만 된단다.
Python 공부와 영어 공부를 한 번에 해결할 수 있다! (원영적 사고!)

강의를 꾸준하게 듣게 하기 위해 여러가지 수단을 동원하는 듯~ ^^

가장 멋진 부분 !!!
실습을 하는 환경도 하나의 화면에 같이 제공을 해준다 !!!

그냥 일반적은 그런 Python 초보 강의가 아니다.
"AI Python" 제목을 달고 있는 강의이다.
어떤 차이가 있냐고?
실습 프로젝트 자체가 다르다.
- Custom Recipe Generator(맞춤형 레시피 생성기): Create an AI-powered tool that generates unique recipes based on available ingredients. You’ll use variables, f-strings, and AI prompts to craft personalized culinary creations.
- Smart To-Do List(스마트 할 일 목록): Build an intelligent task manager that not only stores your to-do items but also prioritizes them using AI. You’ll apply your knowledge of lists, dictionaries, and decision-making code to enhance productivity.
- Travel Blog Analyzer(여행 블로그 분석기): Develop a program that reads travel blog entries and uses AI to extract key information like restaurant names and popular dishes. This exercise showcases your ability to work with files and leverage AI for text analysis.
- Dream Vacation Planner(꿈의 여행 일정 설계자): Create a sophisticated itinerary generator that takes a multi-city trip plan and uses AI to suggest daily activities, including restaurant recommendations. You’ll work with CSV files, dictionaries, and AI prompts to build this comprehensive travel tool.
- Data Visualization Project(데이터 시각화 프로젝트): Using popular Python libraries like matplotlib, you’ll create visual representations of data. This could involve plotting price trends of used cars or visualizing travel statistics from your vacation planner.
- Web Data Extraction(웹 데이터 추출): Use the BeautifulSoup library to scrape web pages and extract useful information, opening up a world of data for your projects.
- Real-time Data Application(실시간 데이터 응용 프로그램): Build a program that interacts with web APIs to fetch and process real-time data, such as current weather information or live currency exchange rates.
AI와 Python에 관심이 있는 초보자들을 대상으로 하고 있는 훌륭한 강의이다.
이 모든 것이 무료로 제공되는데도 공부를 하지 않는 다면 .... 반성해야 한다!!!
'Programming > Python' 카테고리의 다른 글
| 파이썬의 역사 (Python History) (0) | 2025.11.01 |
|---|---|
| 판다스 보다 100배 빠른 불오리들 (FireDucks) (1) | 2024.12.29 |
| NAVER API를 이용해서 블로그 검색하기 (with Python) (0) | 2024.11.23 |
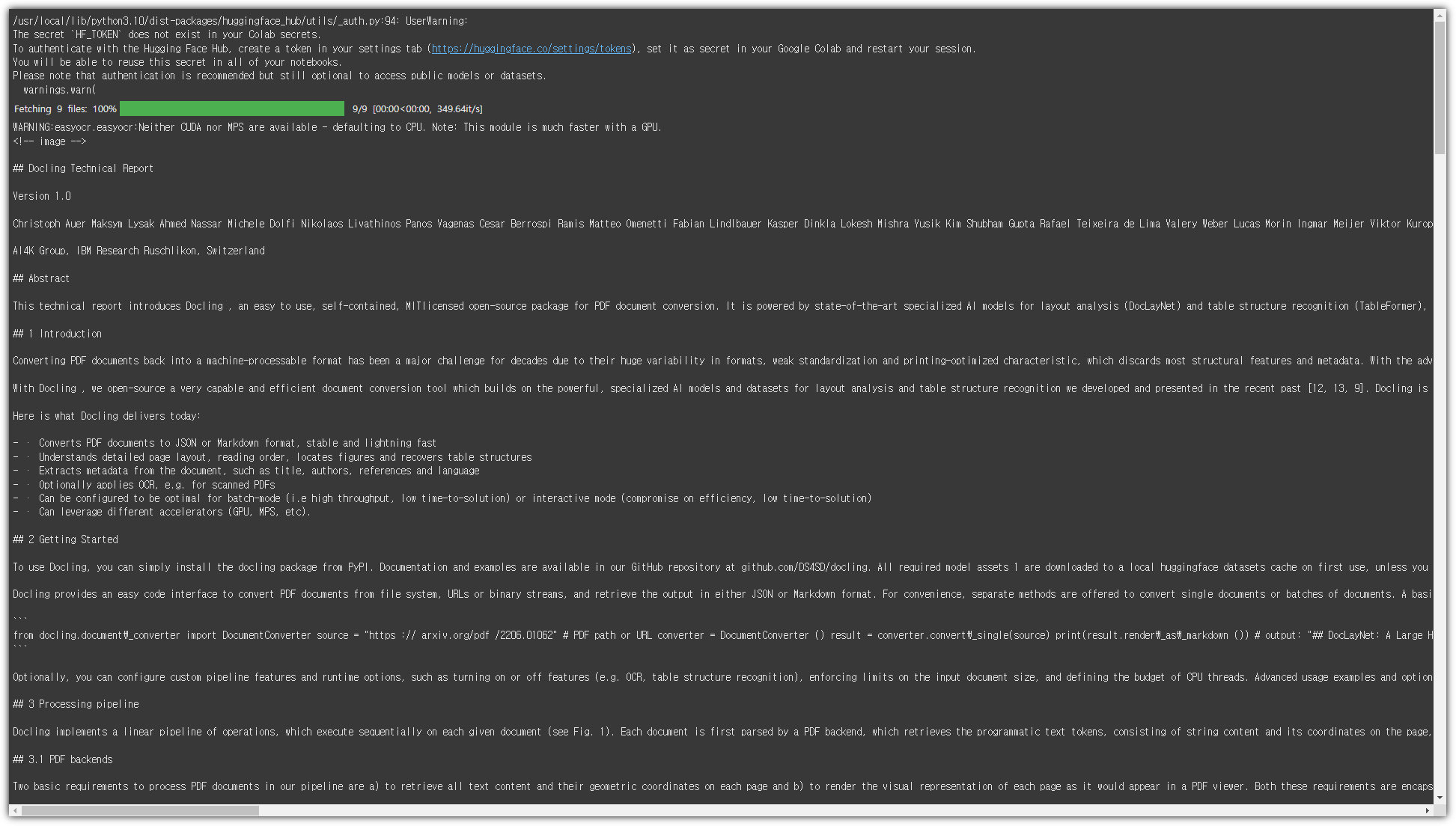
| 문서 파일을 데이터로 만들어주는 Docling (0) | 2024.11.18 |
| FastHTML - 파이썬으로 웹앱 만들기 (0) | 2024.09.23 |