"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."

"박해선"님의 명작 도서, "혼자 공부하는 머신러닝+딥러닝"의 "개정판"이 나왔다 !!!
AI 관련하여 공부를 했던 사람들이라면 아마도 모두 가지고 있을 책이 아닐까 싶은데,
물론 나도 기존 도서를 가지고 있어서 비교 사진을 찍어봤다.

동그라미도 하나 추가되었고, 페이지도 더 많아진 새로운 개정판이다.
그래서인지 정가도 2.6만원에서 3.2만원으로 인상되었다. ㅋㅋㅋ

초판 발행 뒤, 4-5년 정도가 지났으니 물가 인상을 고려하면 정가 인상에 대해서도 충분히 이해가 간다!
벌써 4-5년이 흘렀다니... 처음 이 책으로 공부했던 때가 어제 같은데...
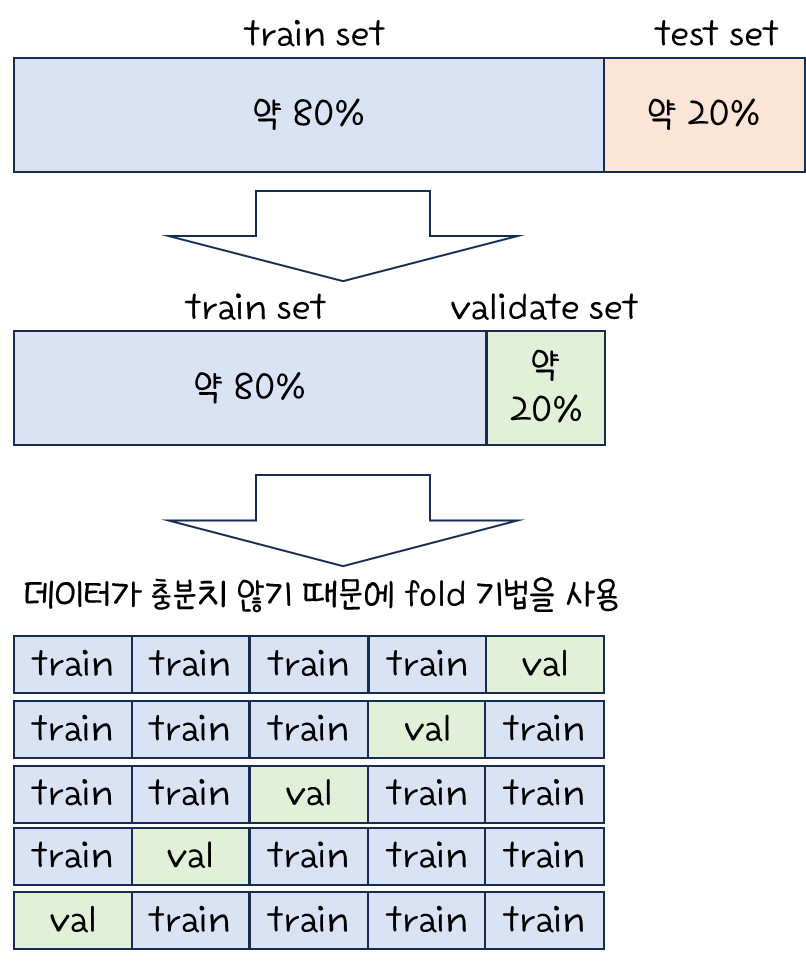
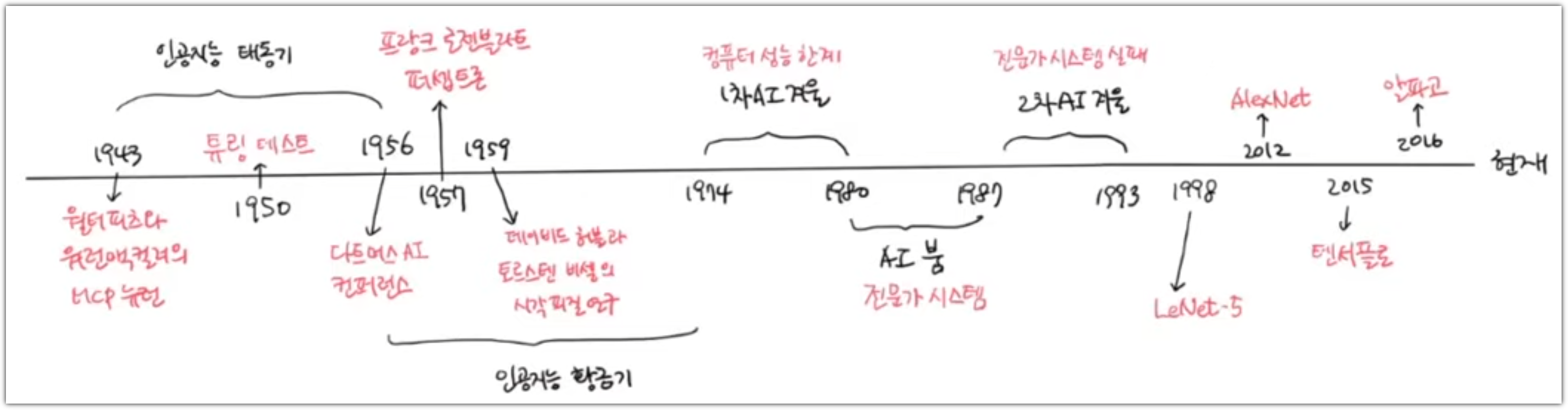
이 책의 장점은 머신러닝에서부터 딥러닝까지 전반적인 사항을 모두 담고 있다는 것이다.

책에서도 말해주다 싶이, 반드시 순차적으로 공부해야하는 것은 아니다.
머신러닝에 대해서 공부하고 딥러닝을 살펴보는 것이 도움이 되기는 하지만,
필수는 아니기에 과감히 점프하고 딥러닝을 공부하는 것도 나쁘지는 않다.

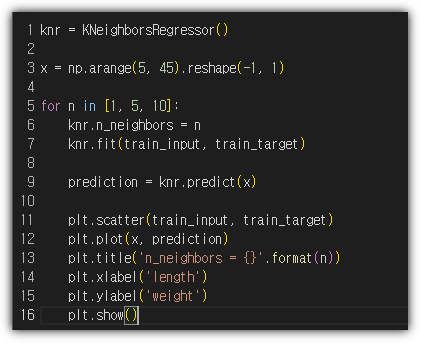
이 책의 초판이 나오는 시점에서는 Tensorflow가 많이 사용될 때라 괜찮았지만,
최근에는 대부분 Pytorch를 많이 사용하기에 개정판에서 파이토치에 대한 내용을 추가해 준 것은 정말 반갑다.
혼공 시리즈의 책답게 동영상 강의도 멋지게 제공을 해준다.
- https://www.youtube.com/playlist?list=PLJN246lAkhQihHwcbrZp9uuwgxQen5HS-

큰 변화가 없는 챕터의 경우에는 기존 동영상 강의를 재활용하셨을거라 생각했는데, 전부 새로 등록하신 것 같다! 와우!
깃허브에 친절하게도 주피터노트북 파일들을 모두 등록해주셨다.
- https://github.com/rickiepark/hg-mldl2
"박해선"님의 블로그를 참고하면 좋다. 정오표도 확인할 수 있다.
- https://tensorflow.blog/hg-mldl2/
개인적으로 처음에 공부할 때에 이 책을 보고선 좀 당황한 적이 있었다.
다른 곳에서 설명하는 것들과는 조금 다른식으로 접근하거나 설명하는 것들이 있어서였다.
그래서 잠시 이 책을 끊고(?) 이렇게 저렇게 시간이 흘러
"혼공학습단"을 통해 다시 이 책을 공부해 보고자 시작하게 되었는데 !!!
머신러닝이나 딥러닝을 조금 공부하고 다시 이 책을 봤더니 감탄을 할 수 밖에 없었다.
아! 이래서 박해선님이 이 부분을 이렇게 설명을 하셨구나!
혼자 공부할 수 있도록 잘 정리되고 친절한 설명이 되어 있는 책이지만,
사실 이 책의 일부 챕터만 가지고도 책 한권이 나올 수가 있을만큼
크고 방대한 내용을 다루는 책이 바로 이 "혼공머신"이다.
그렇기에 이 책을 제대로 공부하기 위해서는 좀 더 꼼꼼하게 살펴보는 것을 권해본다.
이 책에 대해서 서평을 한 마디로 남겨 본다면,
"머신러닝, 딥러닝"을 공부해보고 싶다면 무조건 추천해드립니다!!!
'Books' 카테고리의 다른 글
| [한빛미디어] 혼자 만들면서 공부하는 딥러닝 (혼만공딥) (0) | 2025.06.24 |
|---|---|
| 네? 사내 시스템을 전부 혼자 관리하는 저를 해고한다구요? (9) | 2025.06.15 |
| [한빛미디어] NLP와 LLM 실전 가이드 (4) | 2025.03.23 |
| [파이썬 데이터 분석가 되기] 08 - Homework (1) | 2025.03.10 |
| [파이썬 데이터 분석가 되기] 07 - PRJ: Medical (0) | 2025.03.02 |