GitHub Actions에 대한 첫 이야기는 아래 글을 참고하면 된다.
- https://www.whatwant.com/entry/GitHub-Actions-Quickstart
이번에 살펴볼 것은
Actions에서 자동화 하는 과정에서 Pull-Request의 comment를 작성하도록 할 수 있는 방법이다.
찾아본 결과 총 3가지의 방법이 있는 것 같아서 하나씩 알아보았다.
① actions/github-script
Actions의 YAML 파일 안에서 어느 정도의 프로그래밍을 할 수 있도록
JavaScript 형식으로 지원해주는 기능이다.
`analysys_result.txt` 파일의 내용을 comment로 반영하도록 작성한 것이다.
이거 하나를 위해 알아야할 것들은 많다.

`pull_request`가 처음 생성되거나 변경 사항이 있을 때 동작하도록 설정을 했고,
해야할 일을 수행하기 위해 필요한 permission도 정의를 해줬다.
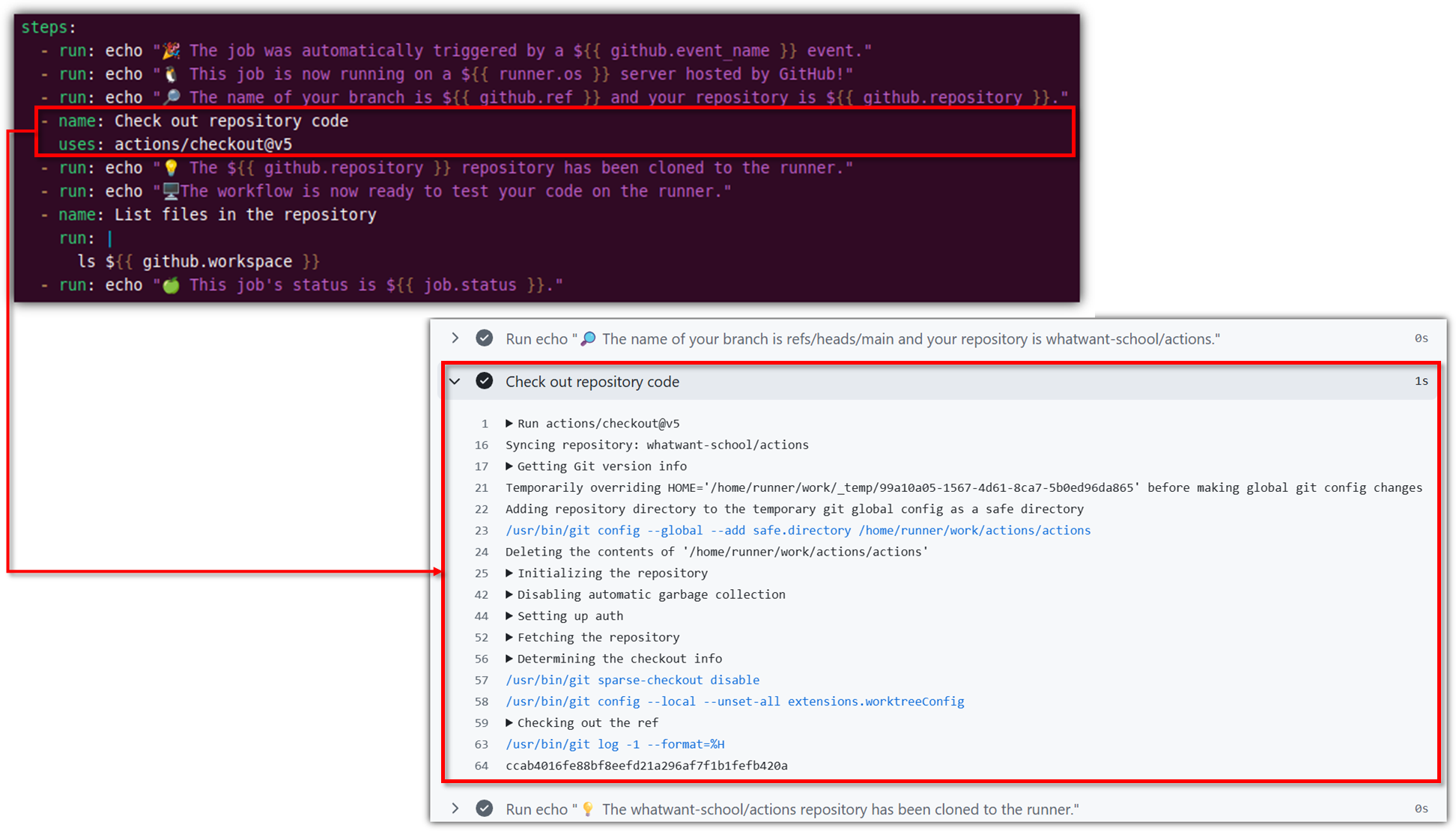
`analysys_result.txt` 파일이 저장소에 있기 때문에
`Check out repository` 과정도 수행하게 했다.

파일이 없거나 여러 상황에 대해서 좀 처리하는 과정까지 포함해봤다.
사실 살펴보면 알겠지만, comment 자체를 반영하는 것은 간단하다.
② community action
자주 사용하거나 아니면 복잡한 기능들을 라이브러리 처럼 만들어서 서로 공유하기도 한다.
물론 GitHub에서 공식적으로 제공해주는 것들도 많다.
- https://github.com/marketplace?type=actions

원하는 기능이 잘 만들어진 것을 선택하면 정말 간단하게 구현이 된다.

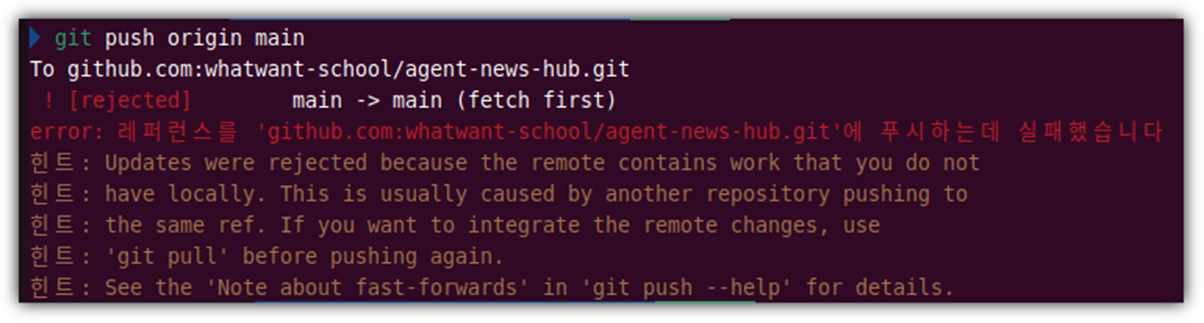
오늘 진행한 내용은 Codex의 도움을 많이 받았는데,
중간에 아래와 같은 에러가 발생했을 때에도 정말 간단하게 처리할 수 있었다.

github.com 환경에서 작업을 하니 링크를 그냥 던져버릴 수 있으니 정말 편했다.
회사에서도 이렇게 할 수 있으면 정말 좋을텐데 ...

③ GitHub CLI
Actions에서 사용하는 ubuntu 이미지에는 GitHub CLI 도구도 기본 설치되어 있다.
그러면 이것을 이용해서 간단하게 작업할 수 있다.

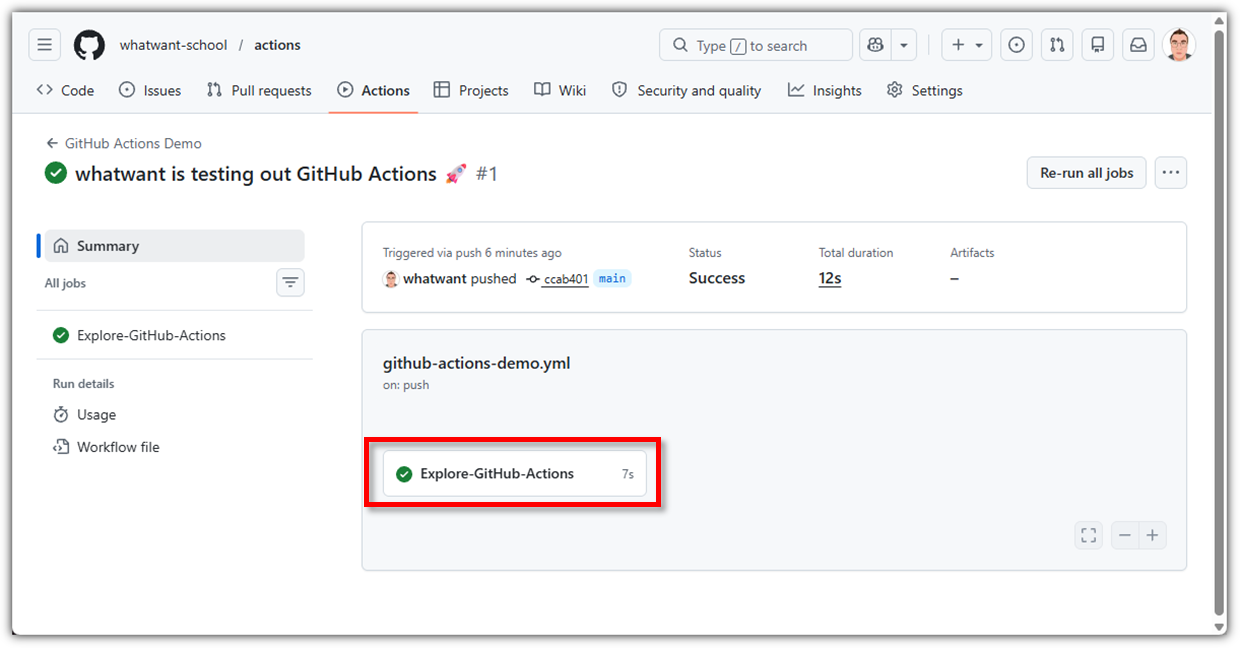
이렇게 Actions workflow 파일을 만들어서 적용시키면 comment를 잘 달아준다.

Action 수행된 결과도 확인해보면 많은 공부가 된다.

이렇게 알아보니 확실히 각각 장단점이 분명한 것 같다.
자유도가 높은 것은 action-script이고, 가장 간단한 것은 community action 가져다 사용하는 것이고,
local에서도 사용할 수 있는 일반적인 방식은 GitHub CLI이고 ... 그런 것 같다.
잘 이용해서 재미있는 것들을 만들어봐야겠다.
'SCM > Git-GitHub' 카테고리의 다른 글
| 다이어그램을 텍스트로 작성하는 Mermaid 알아보기 (0) | 2026.04.17 |
|---|---|
| GitHub Actions 처음 맛보기 (1) | 2026.04.05 |
| 실용적인 코드 리뷰 문화 엿보기 (feat. 뱅크샐러드) (1) | 2026.04.04 |
| Branch protection rules (코드리뷰를 필수로 설정하기) (1) | 2026.03.14 |
| 동시에 여러 브랜치에서 각각 작업하기 (git worktree) (0) | 2026.02.08 |