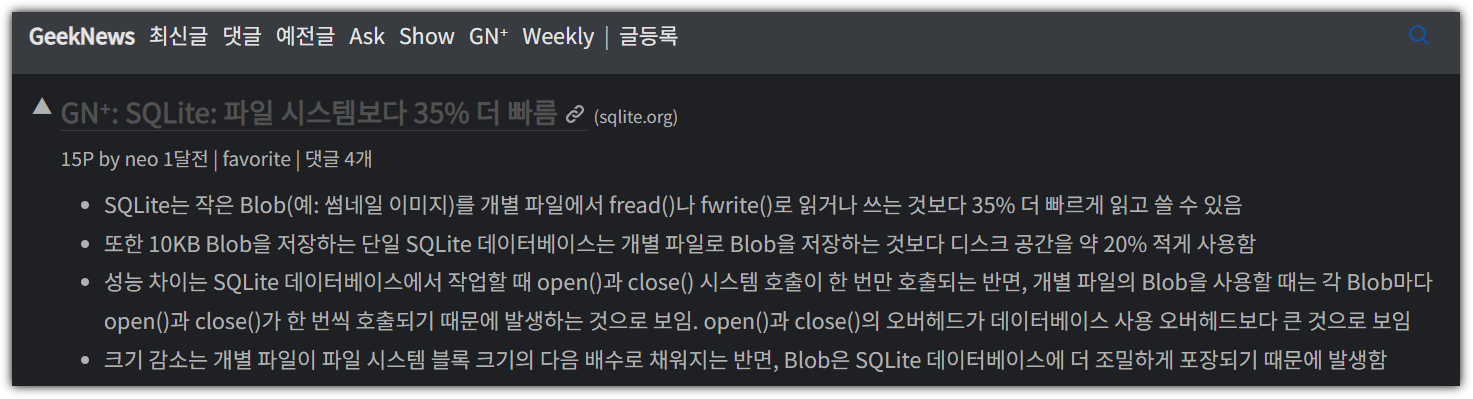
다른 API 테스트 툴을 써보려고 하다가
굳이 시장 지배적인 위치에 있는 Postman을 두고 다른 도구를 써야하나?라는 생각이 들어서... ^^

어?! 사이트 주소가 ".com" 이네!?
이거 회사에서 free 사용해도 되는 것일까?

역시나! 가격 정책이 존재한다.
이거 참... 애매하다.
회사에서 상업적 목적으로 사용해도 되는걸까?
구글링을 해보니 이런 답변이 있긴 하다.
https://gytni.com/new_gytni/qna.php?document_srl=25138&mode=contact&mode2=view&mode3=chk
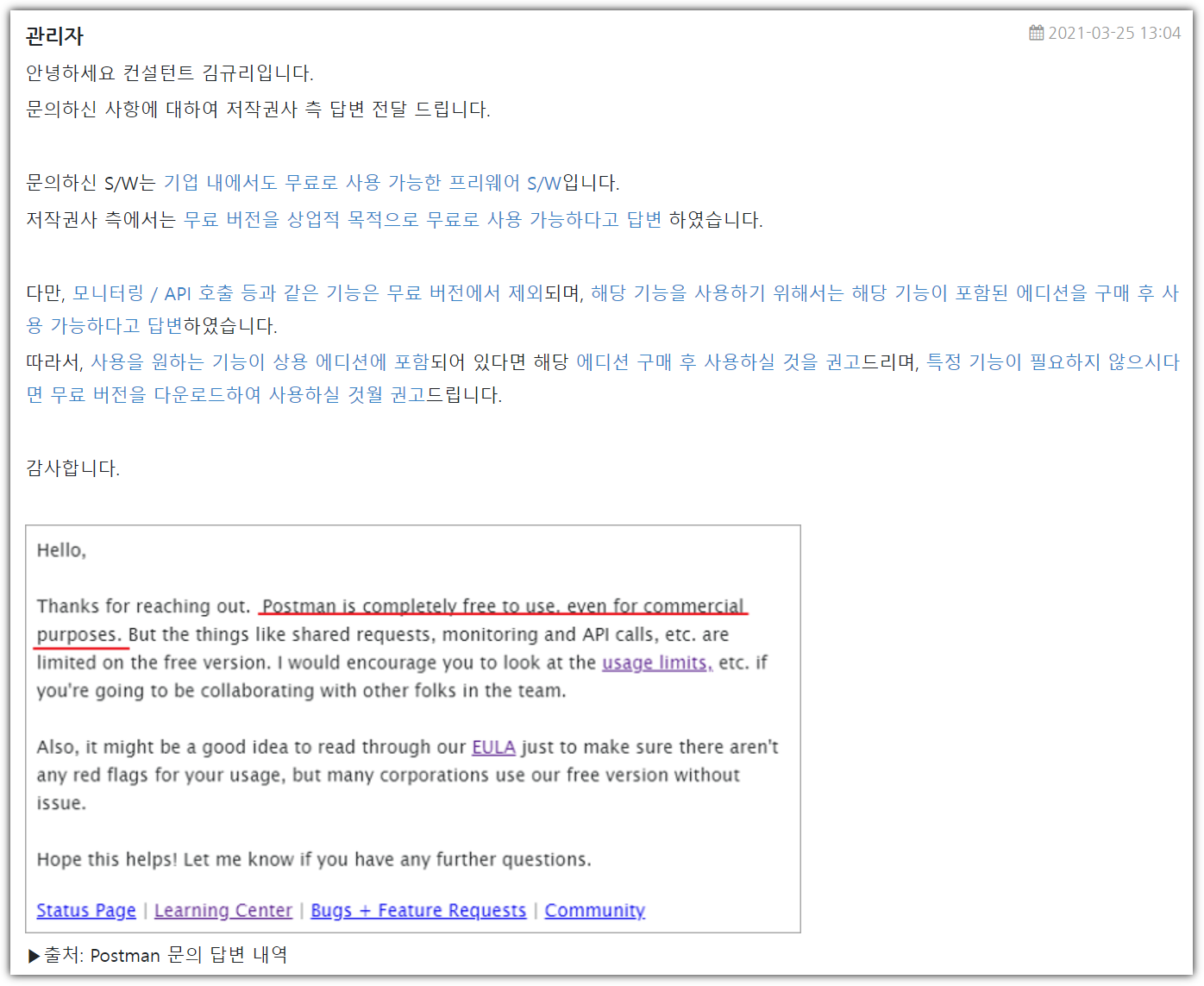
언제든 변할 수 있는 것이 라이선스이고, 가격정책인지라
현재 시점에서도 허용되는 내역인지는 추가 확인이 필요할 것 같다.
법적 해석까지는 모르겠지만,
현재 Terms 내용을 살펴봐도 그렇고, 구글링 결과들을 살펴봐도
회사에서 상업적 목적으로 사용하는 것은 가능한 것으로 보인다.
그런데, 여기에서 하나 더 살펴볼 것이 있다.
위의 가격정책은 플랫폼 서비스로 제공되는 것에 기반한 정책으로 보인다.
다운로드 받아서 직접 설치해서 사용할 수도 있는 것이다.

다운로드 받아서 직접 설치/사용한다고 하여 무조건 free 인 것은 아니지만,
보안 측면에서도 그렇고 여러가지를 검토해봐도 그렇고
회사에서 사용한다고 하면 다운로드 받아서 직접 설치 후 사용하는 것이 안전하다고 판단된다.
1. Download
웹사이트를 통해서 다운로드를 받는 것이 가장 편하지만,
개인적인 취향으로 CLI를 통해 다운로드 받는 것을 좋아하기 때문에 다음과 같이 진행했다.
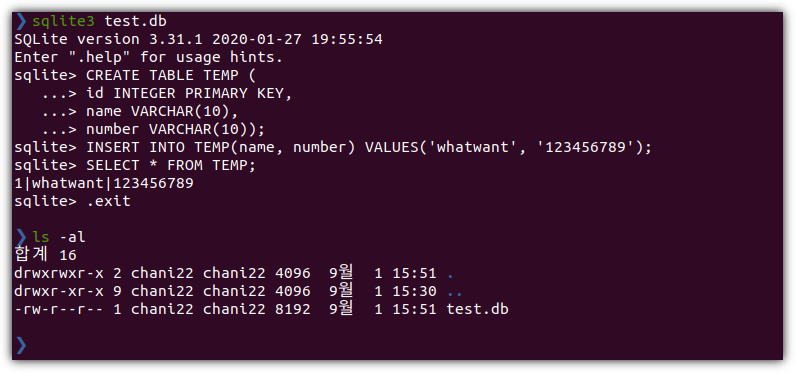
| > wget https://dl.pstmn.io/download/latest/linux64 -O postman-linux-x64.tar.gz |

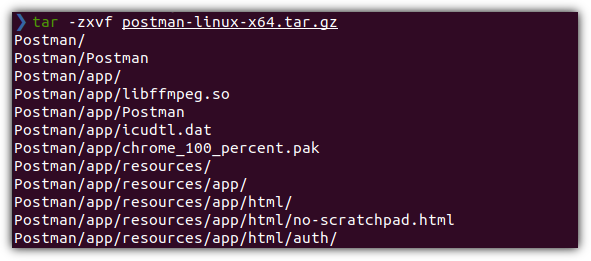
2. Extract
압축 해제를 하면 된다.
참고로 주로 "/opt" 경로를 사용하도록 가이드를 하고 있는데.
개인적인 취향으로 "/srv/install/postman" 경로를 사용했다.
| > tar -zxvf postman-linux-x64.tar.gz |
3. Symlink
실행 경로 등을 위해 symlink 생성을 해주면 좋다.
| > sudo ln -s /srv/install/postman/Postman/Postman /usr/bin/postman |
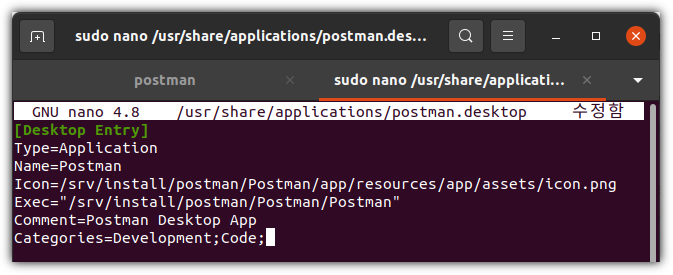
4. Desktop Icon (Optional)
선택적이기는 한데,
GUI에서 편하게 사용하기 위해 아이콘을 만들어 놓으면 좋다.
| > sudo nano /usr/share/applications/postman.desktop |
| [Desktop Entry] Type=Application Name=Postman Icon=/srv/install/postman/Postman/app/resources/app/assets/icon.png Exec="/srv/install/postman/Postman/Postman" Comment=Postman Desktop App Categories=Development;Code; |
오른쪽 아래에 예쁘게 생성되어 있는 것을 볼 수 있다.

5. Execute
실행을 해보자.
위에서 생성한 아이콘을 이용해도 좋고, CLI를 통해서도 실행할 수 있다.

웹 인터페이스가 아니라 Client가 실행된다.

6. Account
계정을 요구한다.
"Create Free Account"를 선택하면...

홈페이지에서 계정 생성하는 화면으로 넘어온다.
굳이 계정을 만들고 싶지는 않은데...
그래서 "Continue without an account"를 선택해보면 다음과 같은 화면을 볼 수 있다.

부족하더라도 "Open Lightweight API Client"를 이용하도록 하자.
7. GUI Client
이제 드디어 원하는 화면을 볼 수 있다.
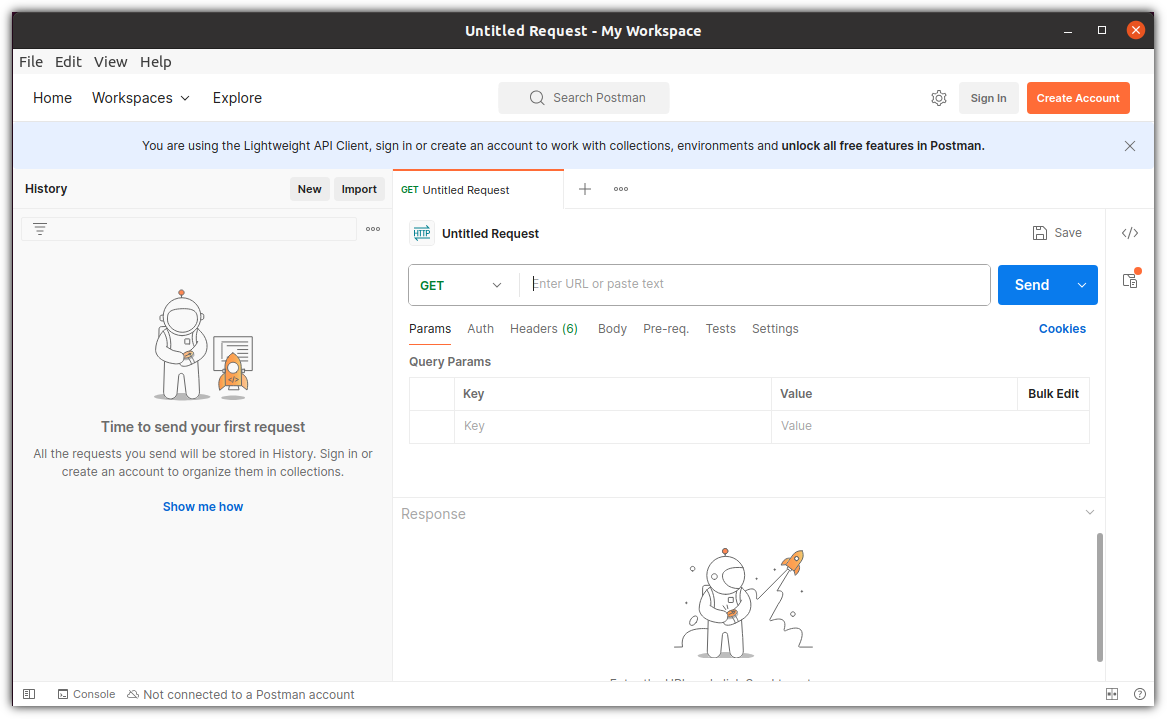
사용법은 다음 포스팅으로 정리해보겠다.
'Dev Tools' 카테고리의 다른 글
| 블로그에서 소스 코드를 예쁘게 보여주기 (2) | 2024.11.14 |
|---|---|
| API 테스트를 위한 Postman (포스트맨) - 기본 사용 (2) | 2024.09.29 |
| 아는 사람만 쓴다는 Config 관리자 - dotenv, dotenvx (1) | 2024.09.18 |
| 개발자를 위한 노트패드(연습장) - Heynote (0) | 2024.01.09 |
| 네트워크(인터넷) 속도 측정 사이트 목록 (0) | 2023.11.13 |