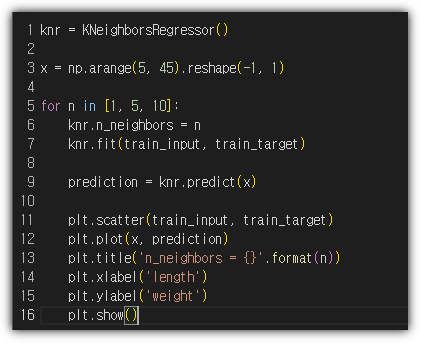
가족 여행 및 대학원 MT로 인해... 엄청난 지각 공부를 한다.
미리 하지 못했음에 대해 반성 !!!! 무릎 꿇고 반성 !!!

05-1 결정 트리 (Decision Tree)
- 로지스틱 회귀 (Logistic Regression)
- 결정 트리 (Decision Tree Classifier), 가지 치기(Prunning)
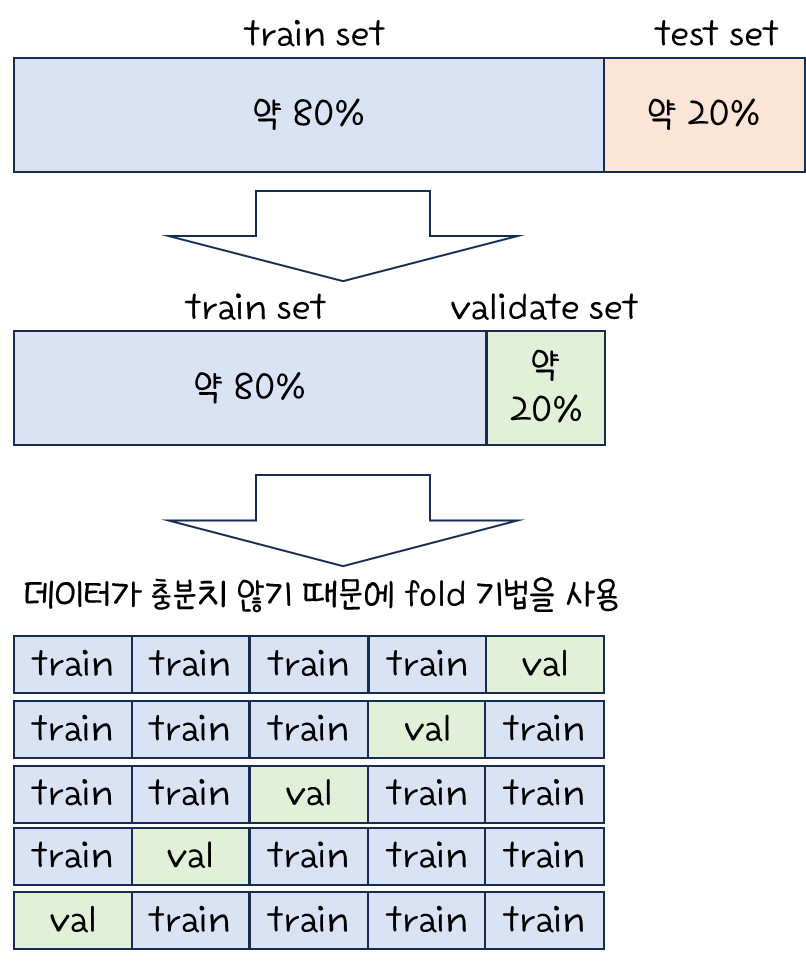
05-2 교차 검증과 그리드 서치
- 검증 세트 (validation)
- 교차 검증 (Cross Validation)
. 분할기(Splitter)를 사용한 교차 검증 : StratifiedKFold
- 하이퍼파라미터 튜닝 (Hyperparameter Optimization)
. 그리드 서치 (GridSearchCV)
. 확률 분포 선택 : uniform, randint
. 랜덤 서치 (RandomizedSearchCV)
05-3 트리의 앙상블 (Ensemble)
- 정형 데이터와 비정형 데이터
. 텍스트/오디오/이미지/영상 등의 비정형 데이터는 주로 DL 에서 취급
- 랜덤 포레스트 (RandomForest)
- 엑스트라 트리 (ExtraTrees)
- 그래디언트 부스팅 (Gradient Boosting)
- 히스토그램 기반 그래디언트 부스팅 (Histogram Gradient Boosting)
- XGBoost vs LightGBM

기본 숙제 : 교차 검증을 그림으로 설명하기
추가 숙제 : 앙상블 모델 손 코딩
- 전체를 캡처하는 것은 무의미한 것 같아, 하단부 부분만 캡처 !!!

반응형
'Books' 카테고리의 다른 글
| [혼공머신] 6주차 - CH.07 딥러닝을 시작합니다 (3) | 2024.08.25 |
|---|---|
| [혼공머신] 5주차 - CH.06 비지도 학습 (0) | 2024.08.16 |
| [혼공머신] 3주차 - CH04. 다양한 분류 알고리즘 (0) | 2024.07.22 |
| [혼공머신] 2주차 - CH03. 회귀 알고리즘과 모델 규제 (0) | 2024.07.14 |
| [혼공머신] 1주차 - CH02. 데이터 다루기 (0) | 2024.07.07 |