"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."

LLM을 현업에서 사용한다고 하면 다들 우려하면서 말하는 것이 바로 "hallucination(환각)" 현상이다.
실무에서는 예측 가능한 것이 중요하고, 정확한 것이 중요한데
LLM 특성상 확률로 결정되는 부분들이 있기에 예상을 벗어난 답변을 할 수도 있고
정확하지 않은 것을 사실인 것 처럼 말할 수도 있는 것이다.
LLM 자체가 확률을 기반으로 하기에 "hallucination(환각)"을 완전히 없앨 수는 없겠지만
어떻게 하면 줄일 수 있는지 그 방법을 배워야만 하는 것이다.

"프롬프트 엔지니어링"이라는 제목을 보고
처음에는 ChatGPT와 같은 웹 화면에서 프롬프팅을 하는 것을 예상했는데,
이 책은 표지에 hint가 있는 것처럼 LLM API를 사용하는 과정에서의
프롬프트 엔지니어링을 설명해주고 있다.
그리고 고맙게도 OpenAI API 뿐만 아니라 Gemini API까지 같이 언급해주고 있어서 실습을 할 때에 마음이 편했다.
사실 공부하면서 API 사용하는 것 정도는 커피값 정도 밖에 안되기에 객관적으로는 별 부담이 아닌데
희한하게 OpenAI API 사용하다보면 뭔가 엄청 부담스럽다(나만 그런가!? ^^).
소심한 나로써는 우리 구글님께서 제공해주는 Gemini API를 사용하는 것도 챙겨준 저자가 참 고맙다.

책에서 추천하는 실습 환경은 "Colab + OpenAI API" 이기 때문에,
사전에 어느 정도 파이썬 프로그래밍에 대해서는 경험해본 사람을 추천한다.
처음에 좀 당황스러운 것은 구글 드라이브 주소를 하나씩 타이핑을 해야하는.... 그래서 나는 친절하게 링크를 !!!
- https://drive.google.com/drive/folders/12-NIX1ks8o5bMzCTGRrkE1GphwTq6K3A

GitHub 주소도 같이 링크를 남겨본다.
- https://github.com/KennethanCeyer/robust-prompting-notebooks

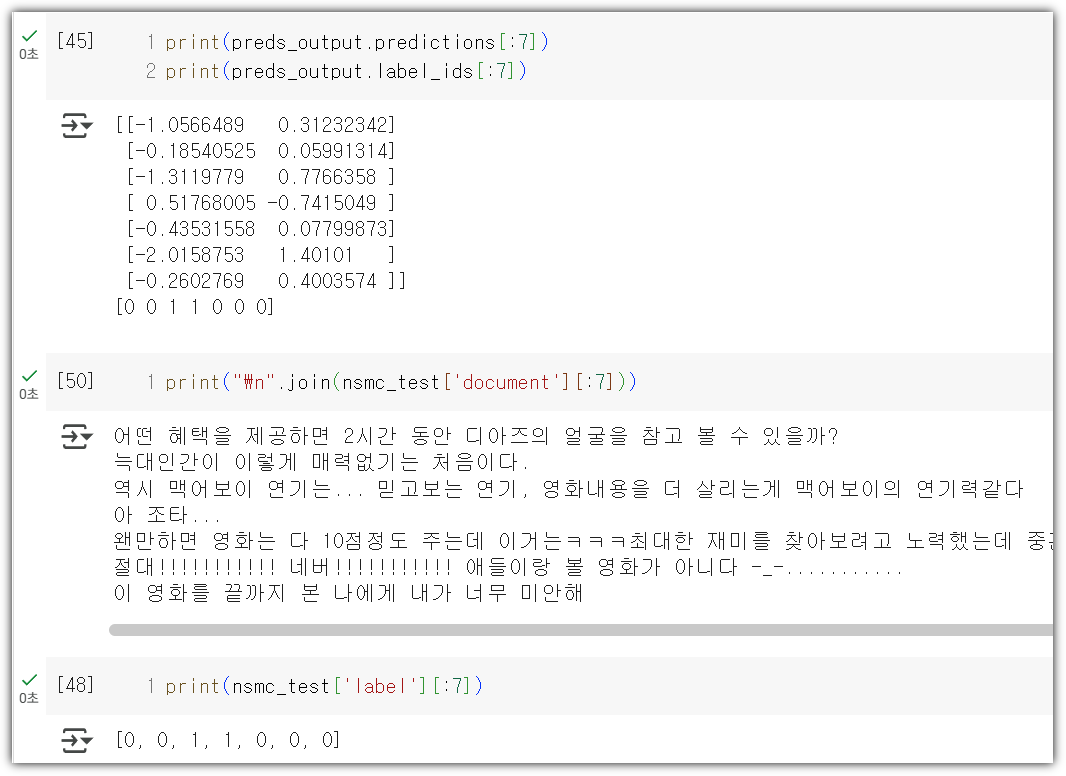
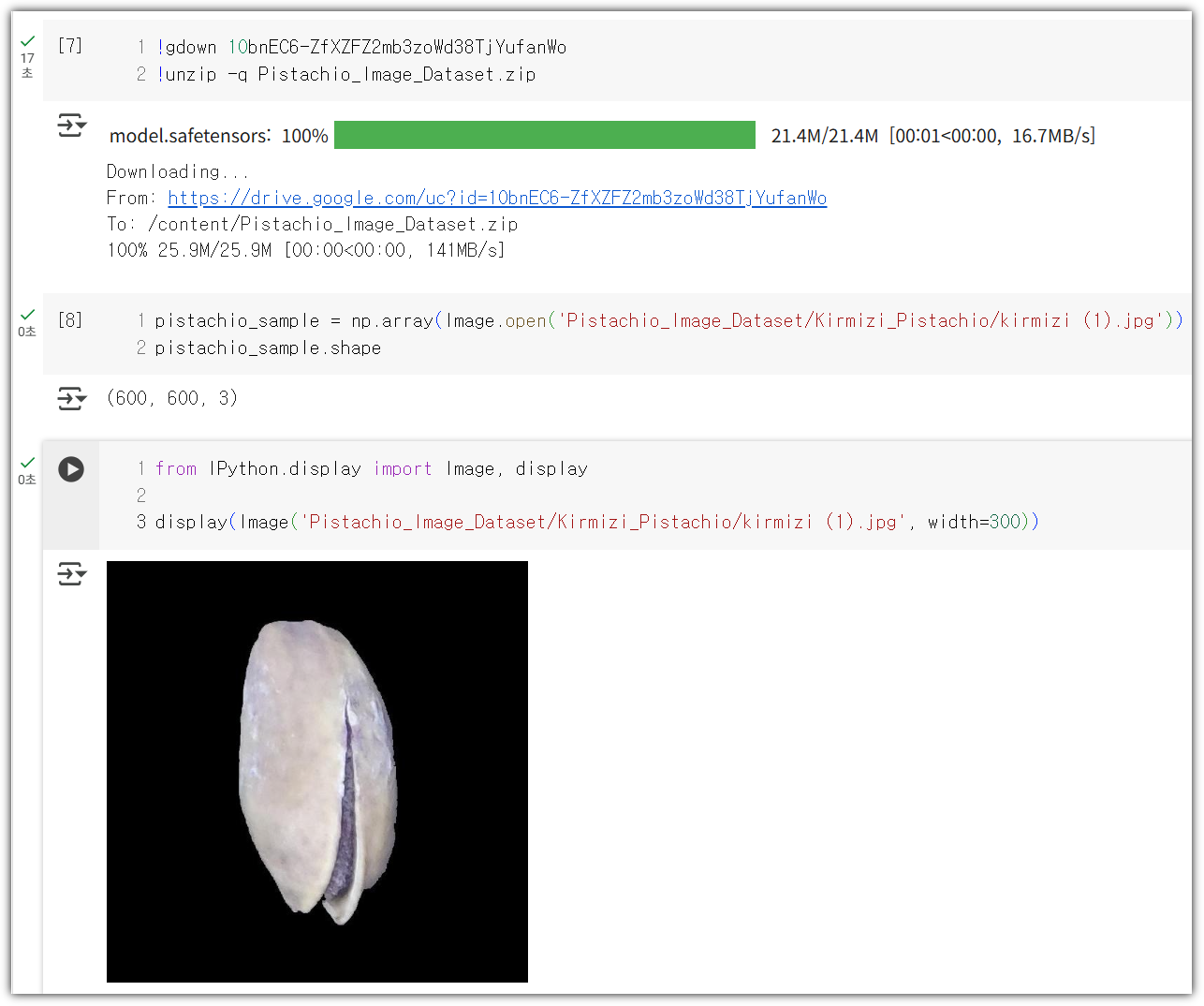
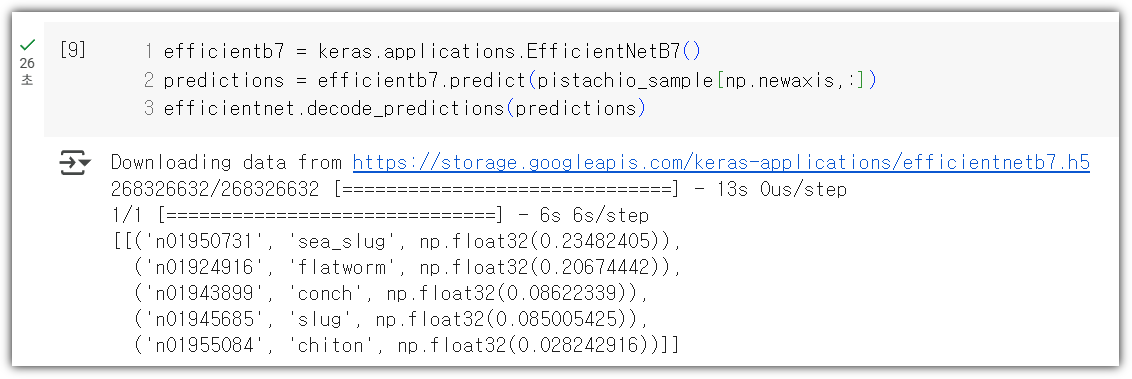
실제 노트북 코드를 보면 아래와 같다.

실제 돌려보면 아래와 같이 잘 나온다.

현업 업무에서 AI Agent 또는 챗봇 같은 것을 개발하다보면
주어진 상황이나 또는 RAG 데이터에 기반해서 정답을 찾아야 하는데
전혀 다른 소리를 하거나 아니면 일반적인 상황에 대한 답변을 하는 경우가 상당히 자주 발생을 한다.
이런 것을 컨트롤할 다양한 방법들을 시도해볼 수 있지만,
프롬프트 엔지니어링이 상당히 중요한 부분이면서 가장 강력한 솔루션이 될 수 있다.
그리고 그러한 프롬프트 엔지니어링을 배울 수 있는 좋은 책이 바로 여기 있다.
"할루시네이션을 줄여주는 프롬프트 엔지니어링"
'Books' 카테고리의 다른 글
| [한빛미디어] 바이브 코딩 너머 개발자 생존법 (1) | 2025.11.23 |
|---|---|
| [길벗출판사] 밑바닥부터 만들면서 배우는 LLM (0) | 2025.11.22 |
| [한빛미디어] 정지훈의 양자 컴퓨터 강의 (2) | 2025.09.28 |
| [한빛미디어] 코드 너머, 회사보다 오래 남을 개발자 (8) | 2025.08.31 |
| 혼공학습단 14기 회고록 (0) | 2025.08.18 |