"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."

책 제목에서 필요한 정보는 다 제공해주고 있다.
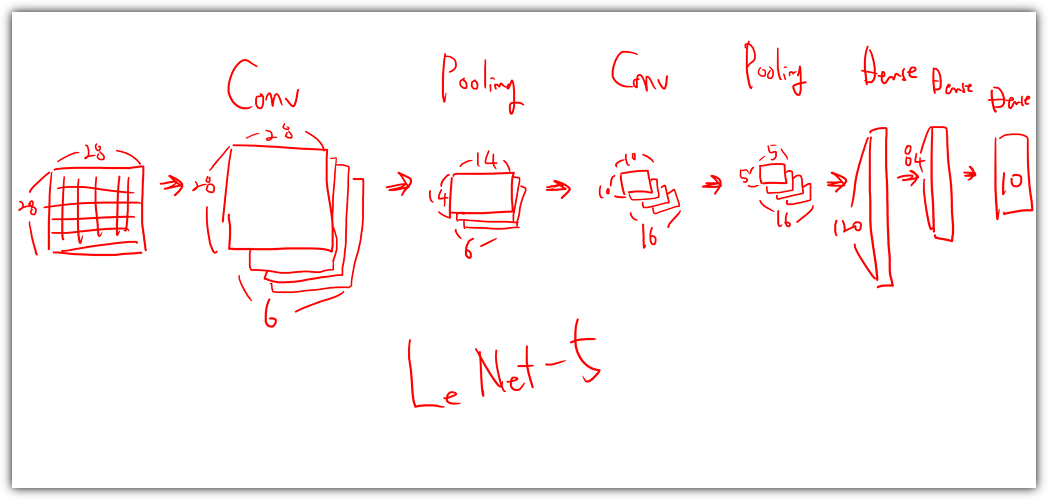
트랜스포머와 디퓨전 모델 기반의 생성형 AI를 실습해보면서 공부할 수 있도록 해주는 책이다.

그것도 6월 30일에 출간한 따끈따끈한 책이다.
참고로 원서는 24년 11월에 출간했다.

이 책은 입문자를 위한 책은 아니다.
파이썬이나 파이토치 등을 써봤고, 머신러닝이나 딥러닝에 대해서 살짝은 공부한 사람들을 위한 책이다.

그리고, 개인적으로 아주 좋아하는 풀컬러 책이다 !!!

최근 빠르게 발전하고 변화하는 AI 세상이다보니
원서의 코드들이 지금 실행하기에 이슈가 있을 수도 있는데,
예제 코드들을 다시 확인하고 정리해서 제공해주신다.
- https://github.com/yk-genai/genaibook

이 책은 총 10개 챕터를 3부로 나누어 구성하고 있다.
| [1부 개방형 모델 활용] 1장 생성 미디어 입문 2장 트랜스포머 3장 정보 압축과 표현 4장 확산 모델 5장 스테이블 디퓨전과 조건부 생성 [2부 생성 모델을 위한 전이 학습] 6장 언어 모델 파인튜닝 7장 스테이블 디퓨전 파인튜닝 [3부 더 나아가기] 8장 텍스트-이미지 모델의 창의적 활용 9장 오디오 생성 10장 생성형 AI 분야의 발전과 최신 동향 |
생성형 AI라고 해서 LLM 중심으로만 설명해주는 것이 아니라
Diffusion Model에 대해서도 설명을 해주면서 이미지 생성에 대해서 충실히 알려주고 있고
9장에서는 오디오에 대한 것 까지도 언급해주고 있다.
그리고, 각 챕터의 뒷 부분에 "연습 문제"와 "도전 문제"를 두어서
이 책을 스터디 용도로 사용하기에도 정말 좋다.
그리고 마지막 10장을 보면 이후에 어떤 주제를 추가적으로 공부하면 좋을지에 대해서도 설명해준다.
정말 공부하고자 하는 사람들을 위해 꼼꼼하게 신경을 많이쓴
충실한 교재라고 볼 수 있다.
반응형
'Books' 카테고리의 다른 글
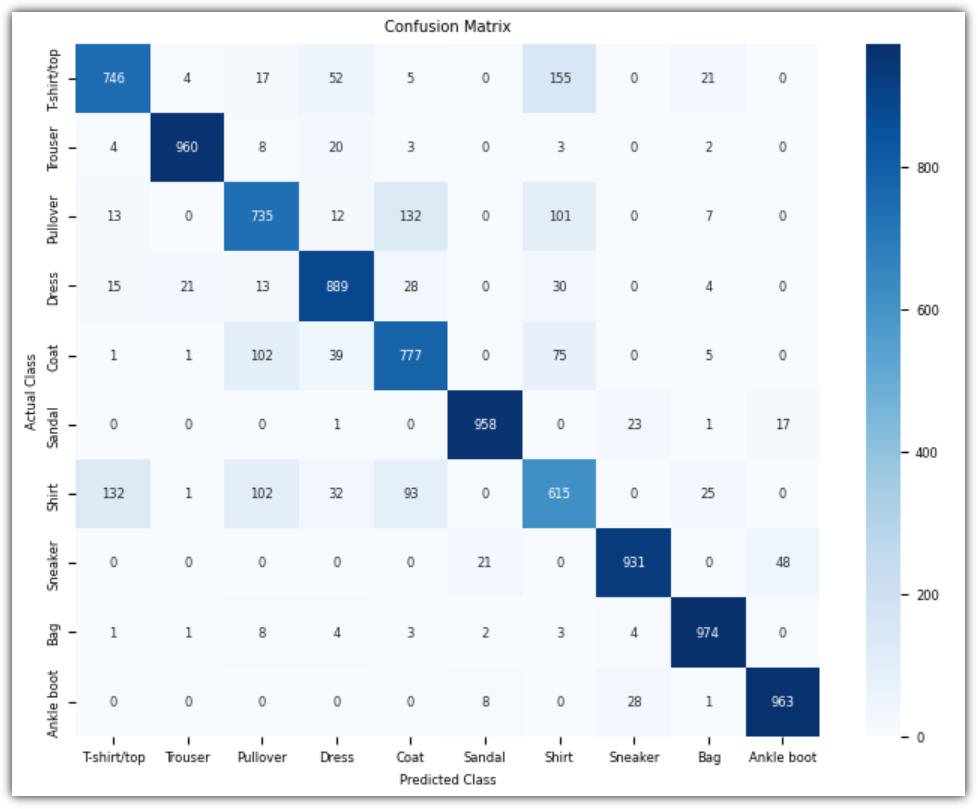
| [혼만딥-5주차] CH03. 고급 CNN 모델과 전이 학습으로 이미지 분류하기 (1) | 2025.08.10 |
|---|---|
| [혼만딥-4주차] CH03. 고급 CNN 모델과 전이 학습으로 이미지 분류하기 (2) | 2025.08.03 |
| [혼만딥-3주차] CH02 사전 훈련된 CNN 모델로 강아지와 고양이 사진 분류하기 (0) | 2025.07.20 |
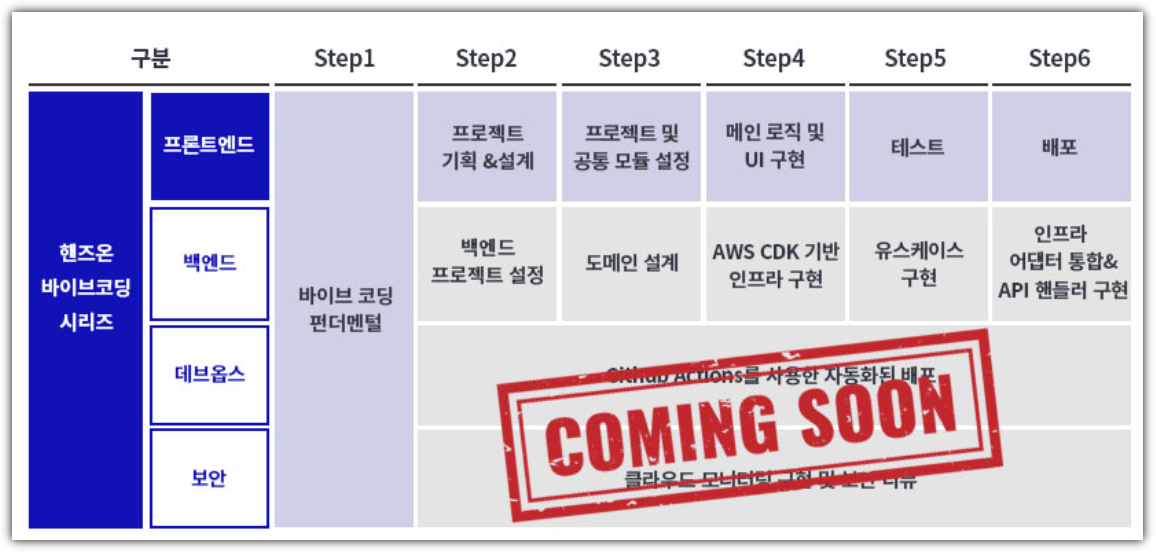
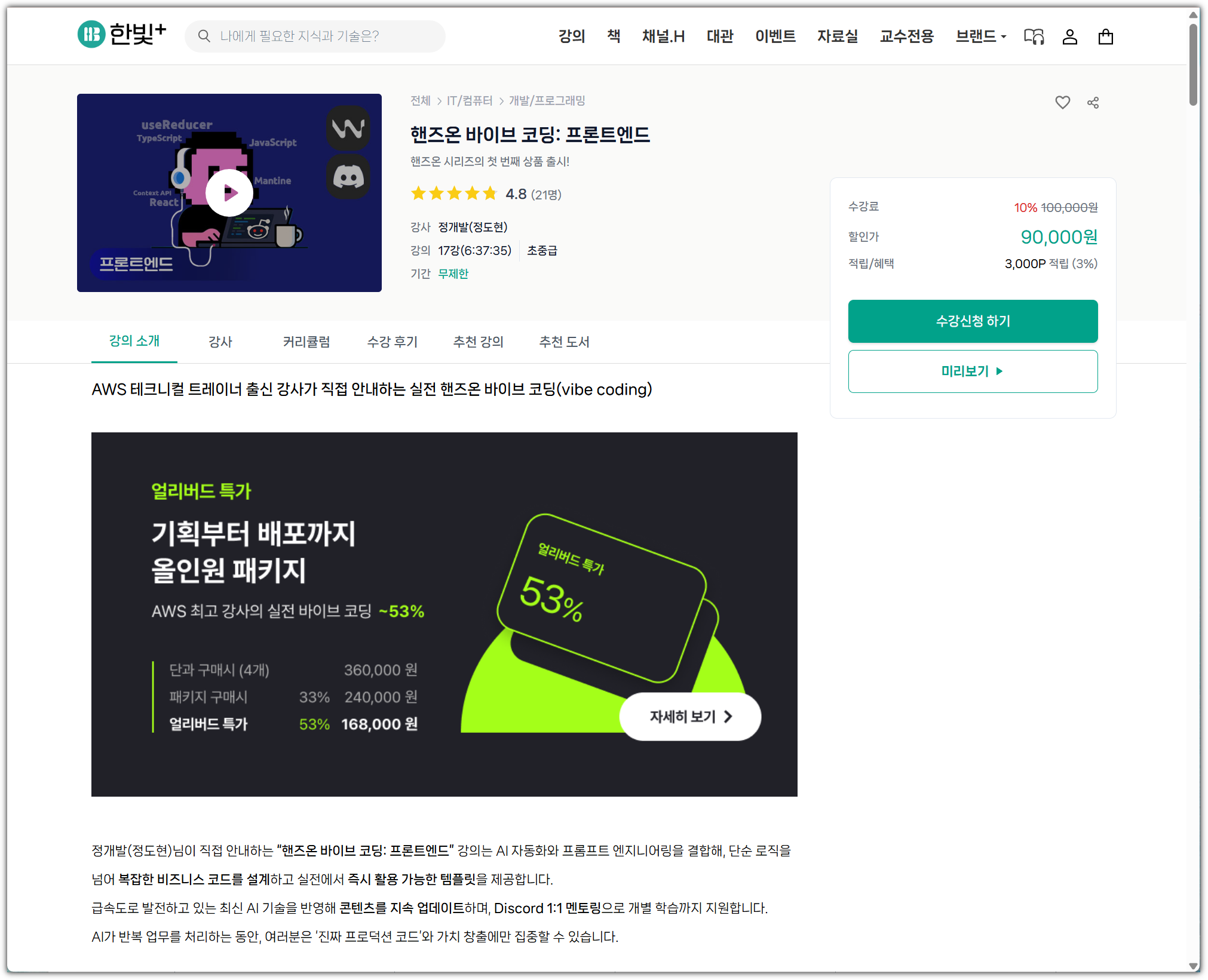
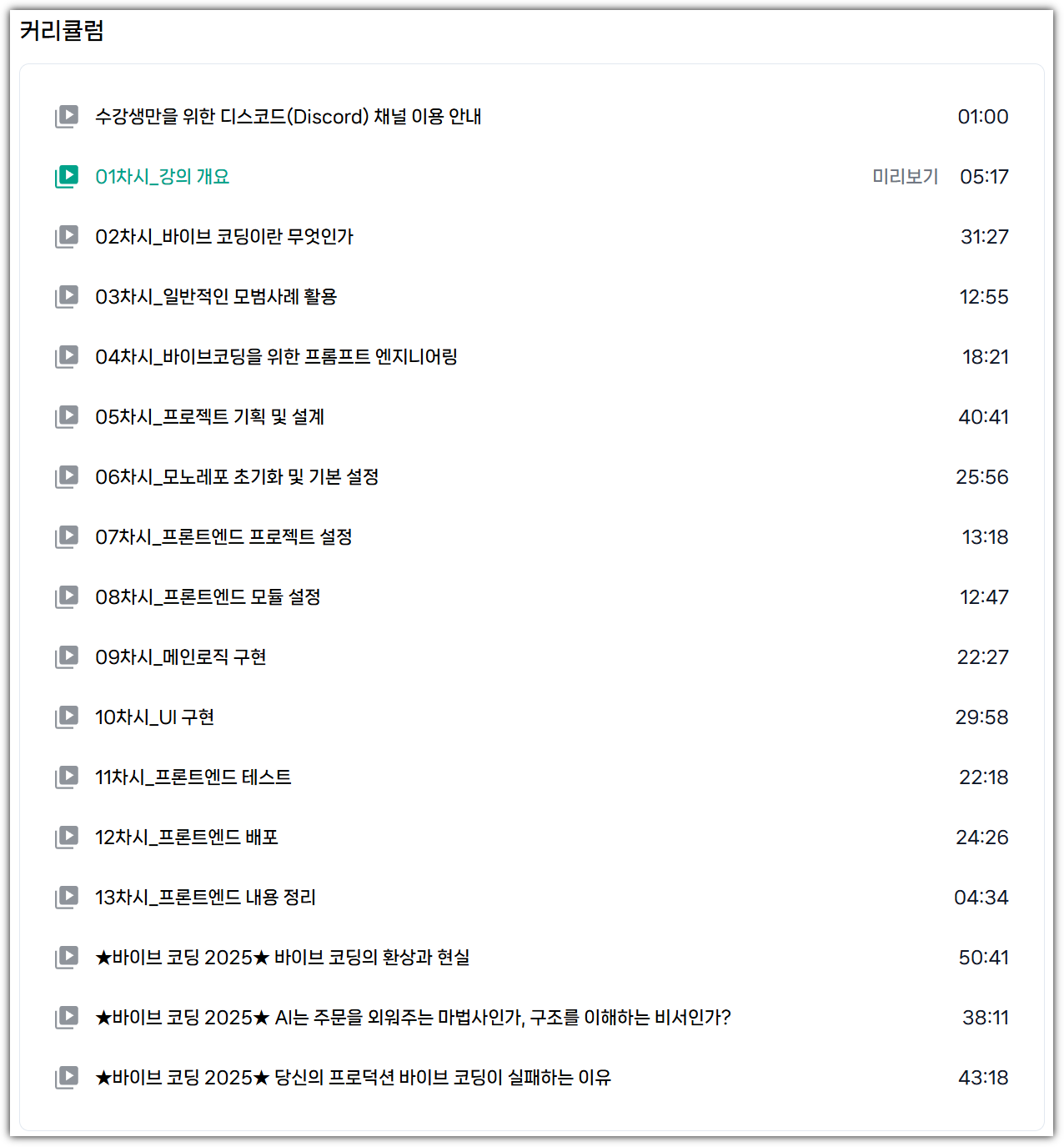
| [강의] 한빛+ '핸즈온 바이브 코딩 - 프론트엔드' 리뷰 (7) | 2025.07.19 |
| [혼만딥-2주차] CH01 합성곱 신경망(CNN)으로 패션 상품 이미지 분류하기 (1) | 2025.07.13 |