"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."

책 표지와 제목만 보고 "멀티 에이전트"만을 위한 책이라고 착각하면 절대 안된다.
"AI Agent"를 개발하고 싶은 분들을 위한 친절한 안내서이다.

eBook을 열어 보자마자 연필로 그려진 저자가 궁금해졌다.
그런데, 책에는 저자에 대한 설명이 없어서 간단하게 검색을 해봤더니, 유명한 분이셨다 !!!

내가 봤던 많은 책의 저자이셨다! 왜 몰랐을까!? 왜 책에 저자 이력을 기재하지 않으셨을까?
아! 그렇구나!!! 진정한 실력자는 그냥 책 내용으로 승부하시는구나 !!!
좀더 찾아서 교보문고에 등록된 프로필을 보니, 역시, 마소 출신의 스페셜리스트 !!! 진정한 고수 !!!
- https://store.kyobobook.co.kr/person/detail/1000509412

이제 책을 보면서 공부를 해보자.
참고로 한빛 전자책을 보면서 2페이지 보기로 공부를 하면서 정말 좋았는데,
듀얼 모니터를 이용해서 하나에서는 책을 보고 다른 모니터에서 코딩을 하는 것이 상당히 괜찮은 사용성이었다.
살짝 아쉬운 것은 책에 있는 URL 등을 copy&paste 할 수 없어서 좀 아쉬웠다.

IT 서적들은 종종 순서대로 읽지 않아도 된다고 말하곤 하는데,
이 책은 심지어 개인 취향에 따라 어떻게 건너 뛰어도 되는지를 친절하게 알려주고 있다.

Chapter 01/02 부분은 이론적인 내용을 설명해주고 있고,
Chapter 03 에서는 실습 환경 준비에 대한 설명이고,
Chapter 04 부터 Chapter 12 까지의 내용은 실제 구현한 Agent에 대한 설명으로만 이루어져 있다.
이 책에서의 실습은 전반적으로 Windows 환경을 기준으로 설명을 해주고 있다.
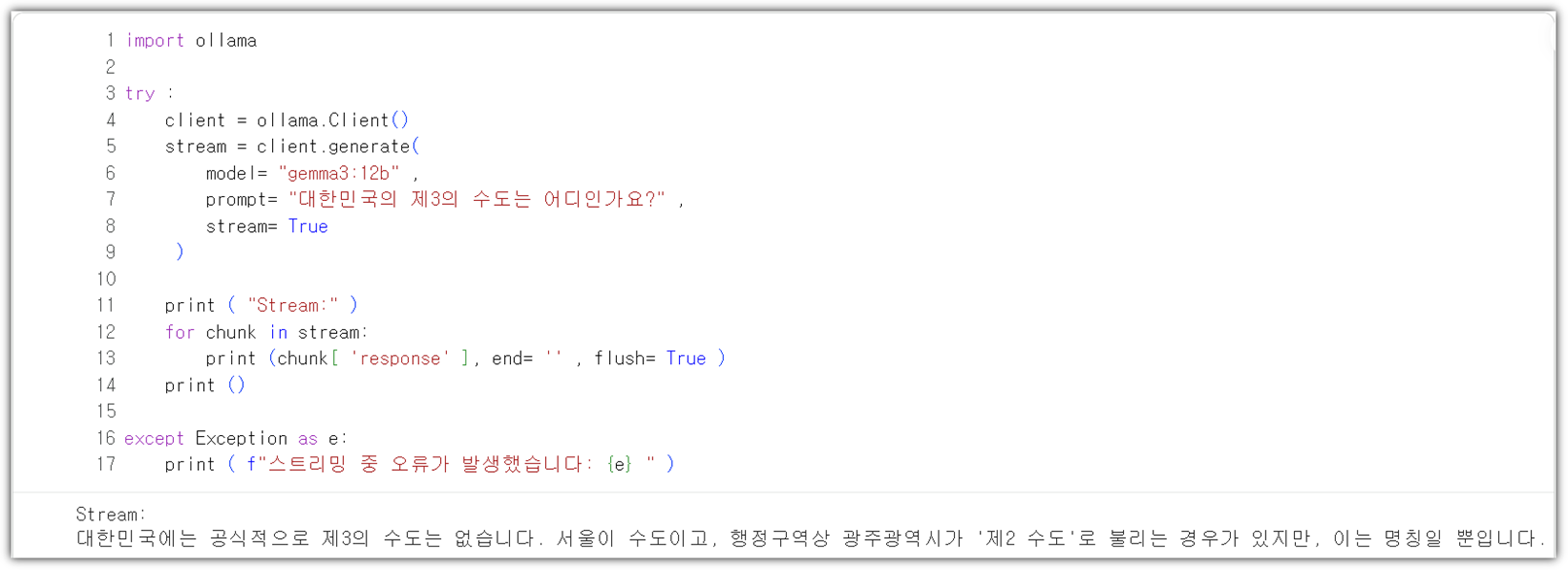
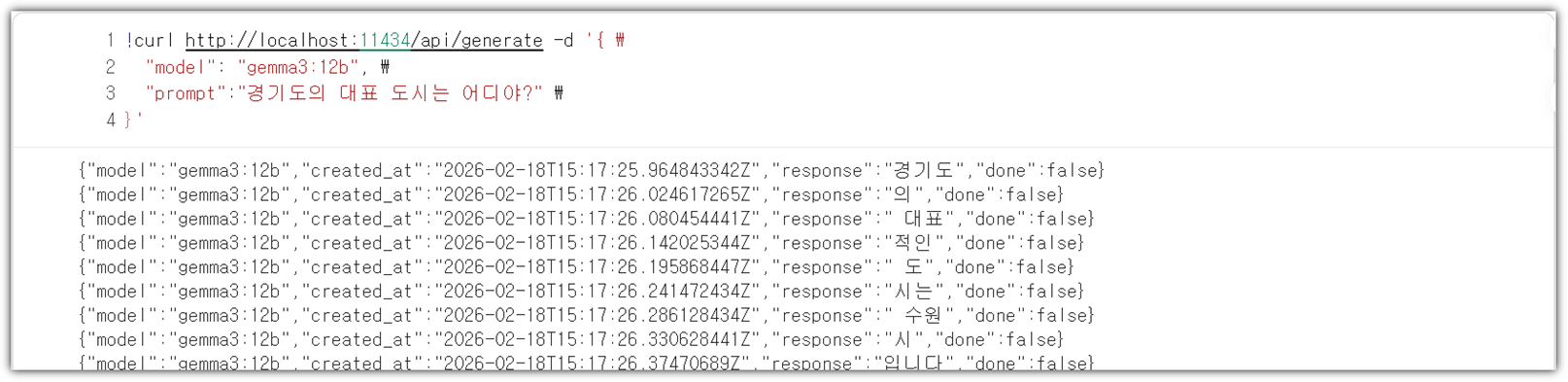
또한 실습을 위해서는 OpenAI(ChatGPT), Claude, Cursor 3종의 외부 생성형AI 서비스를 사용하고 있다고 전제한다.
무료 등급으로도 맛을 볼 수는 있지만 실습을 제대로 하고자 한다면 유료 등급이 필요하다.
책에서 제안하는 운영체제와 서비스들이 물론 당연히 필수는 아니기에,
다른 환경(Ubuntu)과 AI 서비스(Gemini, OpenCode, Openrouter 등)를 사용하겠다라고 하면
발생하는 차이 부분에 대해서는 스스로 깨우쳐 나가야 한다(개인적으로는 가장 많은 공부를 할 수 있는 추천하는 방법이다 !!!)
참고로 MCP 및 FastMCP 부분을 설명할 때,
이 책에서는 패키지를 어떻게 설치하는지 개발환경은 어떻게 맞춰야 하는지에 대한 설명은 하지 않는다.
즉, 이 책은 어느 정도 수준이 있는 개발자를 위한 도서이다.
아쉬운 부분은 실습 코드의 실행도 Windows를 기준으로 구현이 되어 있다는 점인데,
AI를 이용해 Ubuntu에서도 실행이 잘 되도록 개선해보면 공부에 많은 도움이 될 것이다.
이 책을 볼 정도라면 그 정도는 충분하게 ... ?! ^^
Chapter 04 부터는 책에서 설명해주는 내용만 보는 것 보다
실습 코드를 다운로드 받은 다음, VSCode로 열고 GitHub Copilot을 이용해서 질문하면서 살펴보면 훨씬 더 좋다.

이 책은 생성형AI 코딩 에이전트를 이용해 코드 생성 하는 것을 알려주는 책이 아니다.
멀티 에이전트가 무엇이고 어떻게 구성해야하는지에 대한 것을 설명해주는 책이다.
그리고, Chapter 04부터 설명해주는 프로젝트들의 경우 상당히 다양하고 수준 높은 유용한 코드를 제공해주고 있다.
에이전트 개발을 하려는 분들이라면 참고해보면 많은 도움이 될 것이다.
'Books' 카테고리의 다른 글
| [한빛] 클로드 코드 마스터 - AI에게 일자리 지키고자 하는 개발자를 위한 (0) | 2026.05.24 |
|---|---|
| [한빛] 하루 30분 나는 제미나이로 돈을 번다 - 정말 돈을 벌어보자 (0) | 2026.04.25 |
| [한빛] 5분 제미나이 - 구글 사용자라면 제미나이를 써야죠! (1) | 2026.03.28 |
| [한빛] "누구나 아는 나만 모르는 제미나이", 이제는 나도 아는 제미나이? (0) | 2026.02.23 |
| [한빛미디어] 일 잘하는 사람은 이렇게 챗GPT를 씁니다 (0) | 2025.12.28 |