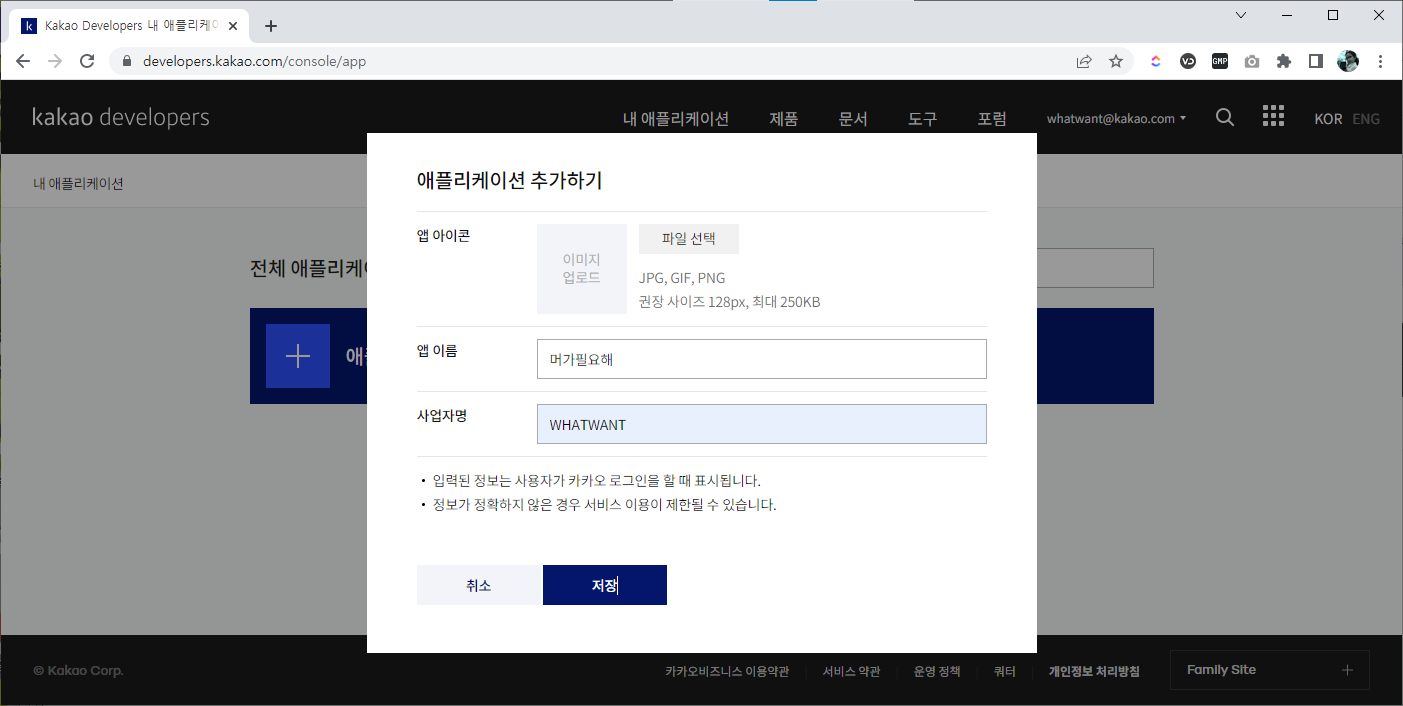
- '앱 이름'과 '사업자명'을 임의로 적어주면 되고, 앱 아이콘은 등록하지 않아도 된다.
애플리케이션 추가
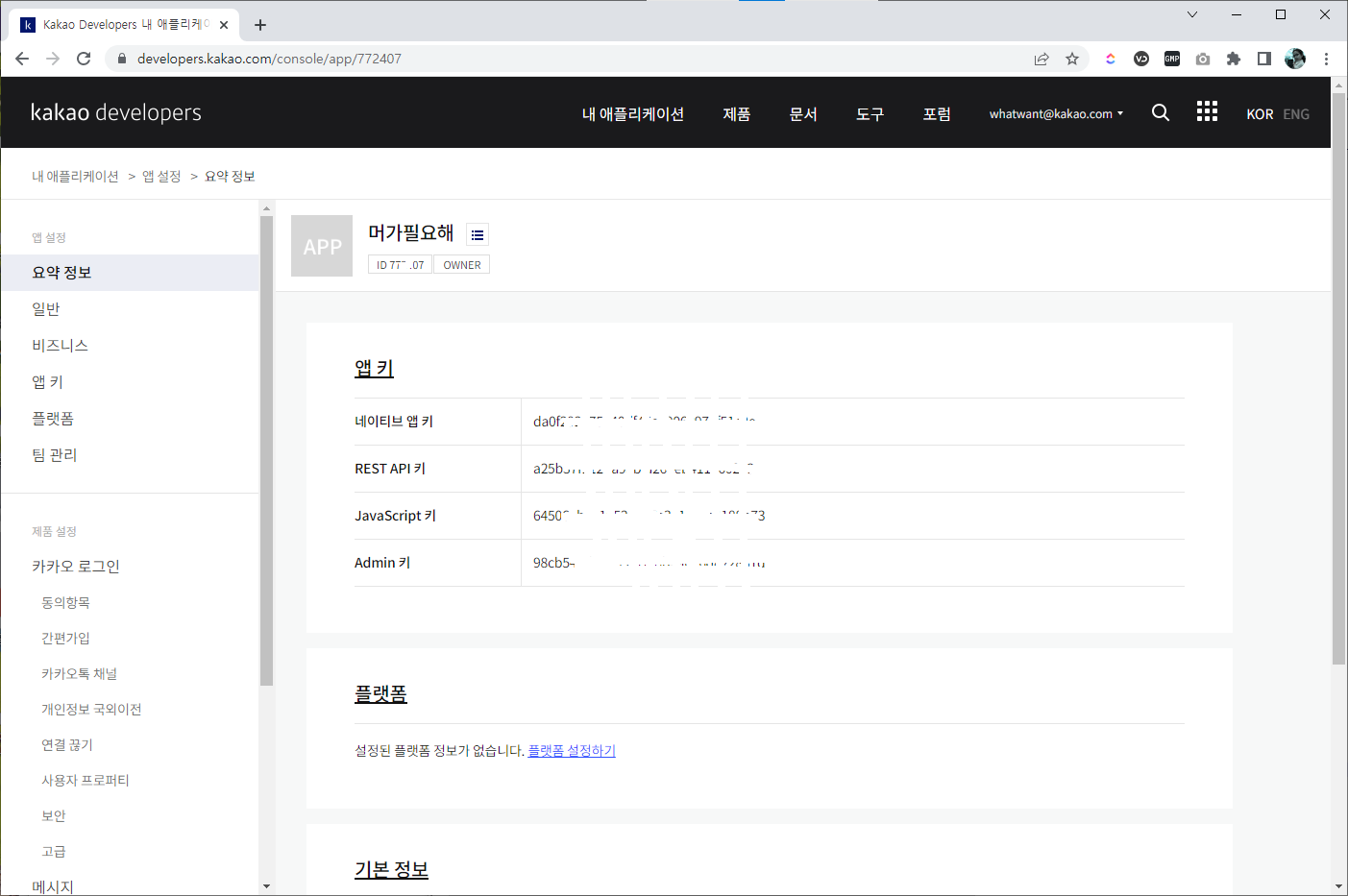
03. 애플리케이션 요약 정보
- 생성한 애플리케이션을 선택하면 다양한 설정을 할 수 있는 화면을 볼 수 있다.
- 첫 화면으로 나오는 요약 정보에서는 중요한 "앱 키"들도 볼 수 있다.
요약 정보
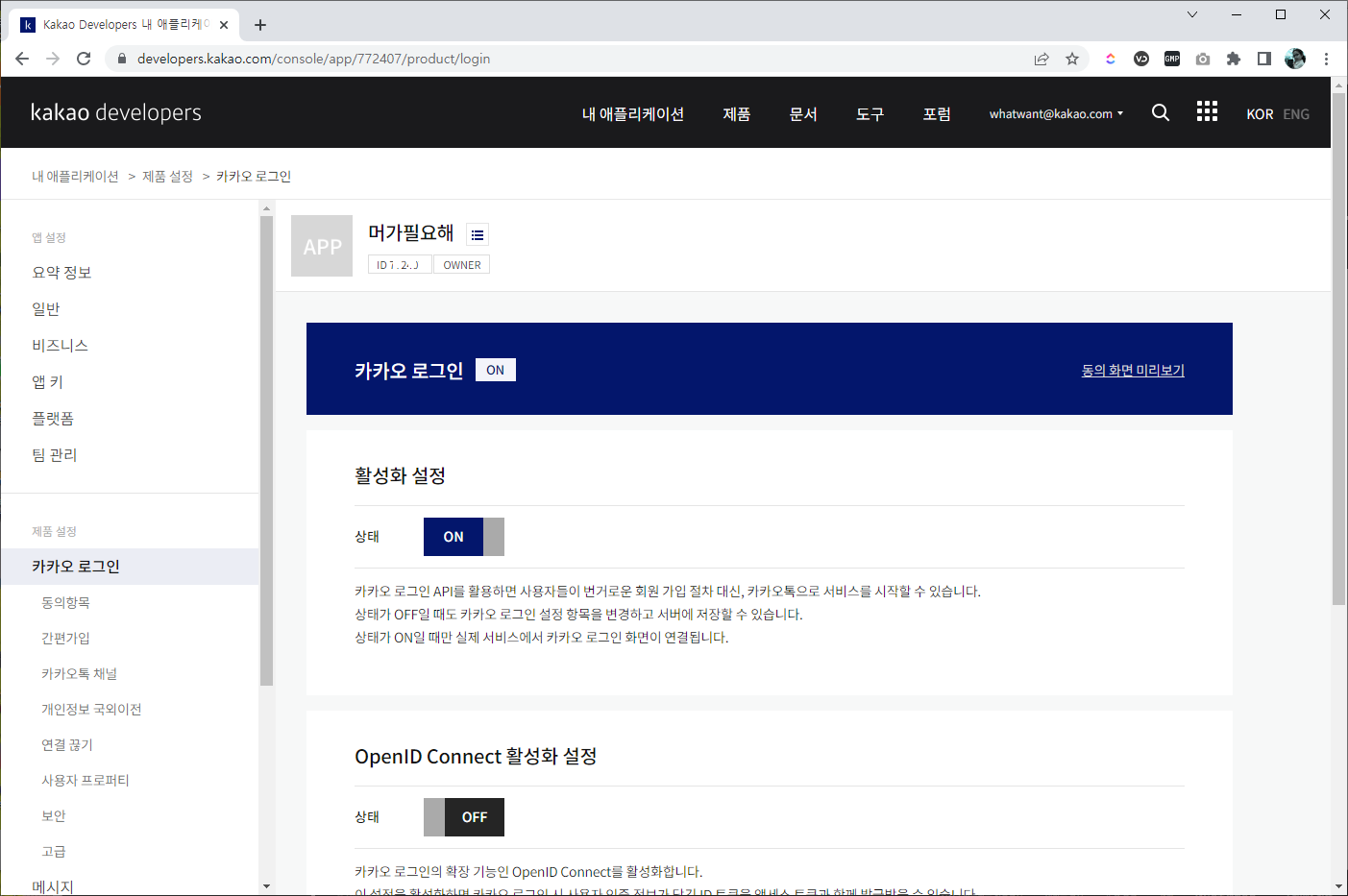
04. 카카오 로그인 활성화
- 카카오 로그인 API를 사용하기 위해서 활성화 설정을 진행해야 한다.
로그인 활성화
05. Redirect URI
- 로그인이 된 다음에 되돌아갈 URI를 등록하는 것이다.
- 지금 마땅히 없으니, 그냥 샘플로 제공되는 주소를 그대로 써주자. (https://naver.com 같이 입력해도 무방하다)
Redirect URI
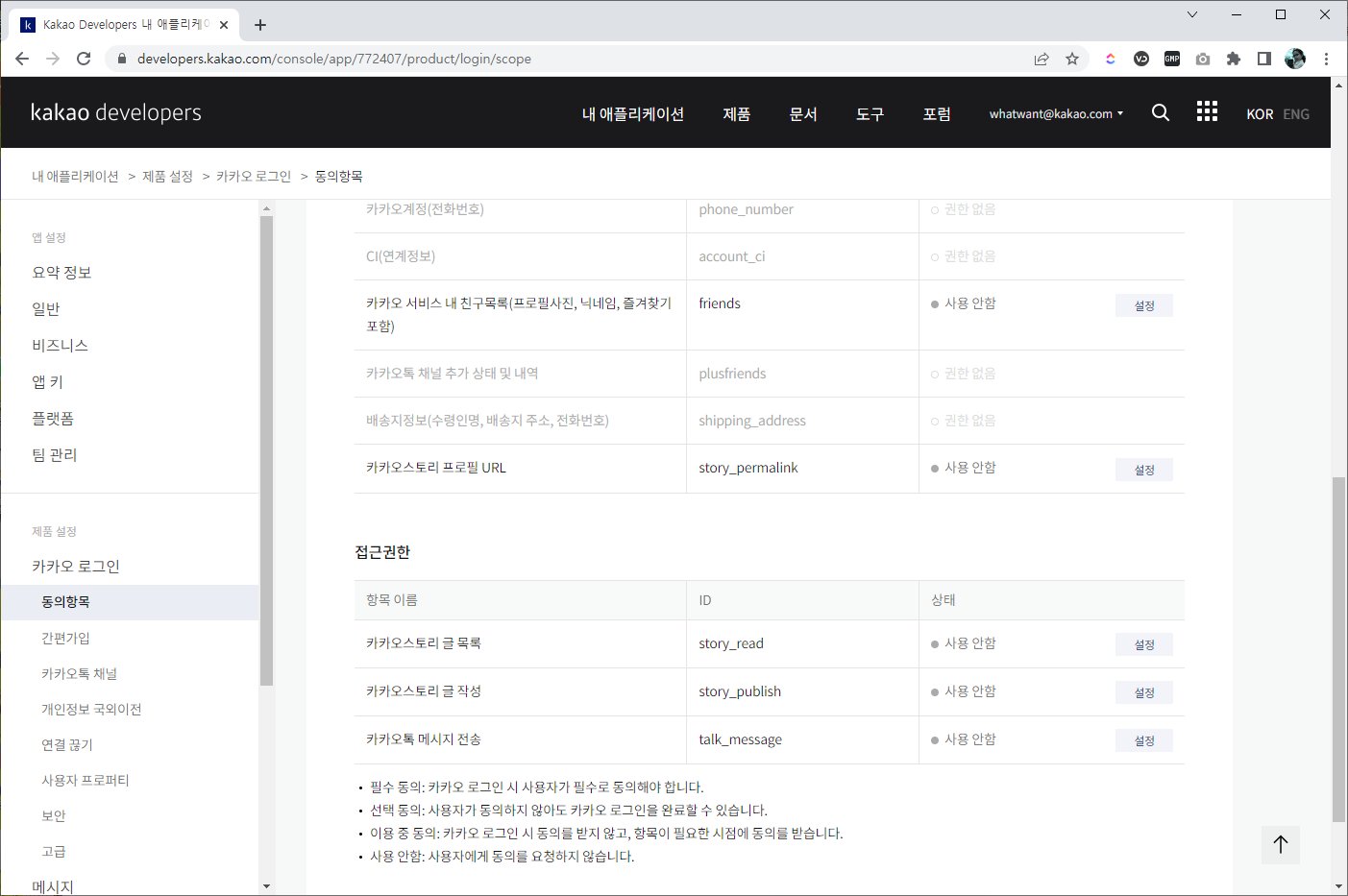
06. 접근 권한
- 사용자 동의가 필요한 접근 항목들이 있다.
- 제품 설정 → 카카오 로그인 → 동의항목 → 접근 권한 → 카카오톡 메시지 전송 → 설정
접근 권한
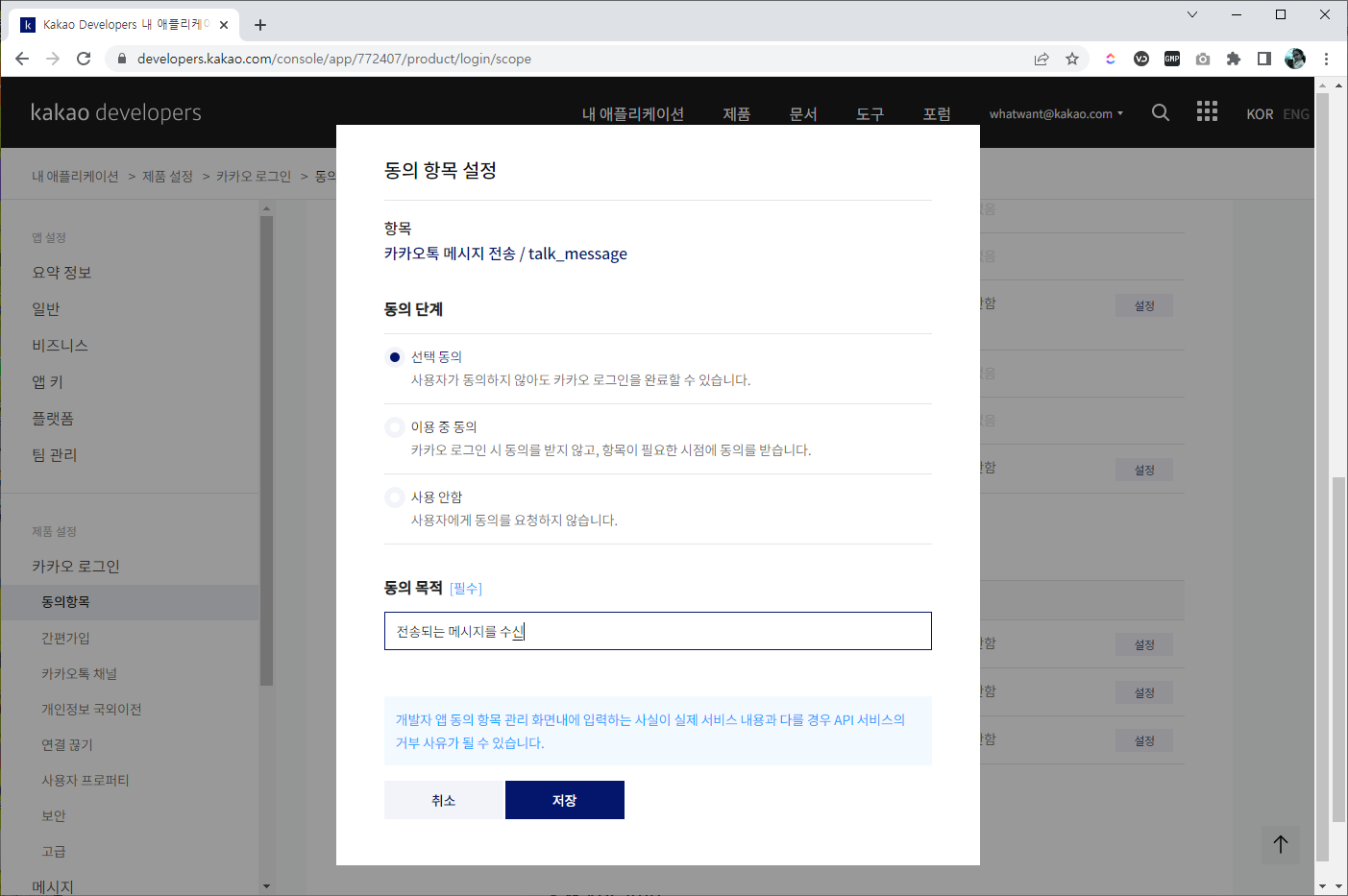
- 아래 화면과 같이 "선택 동의"를 선택하고 "동의 목적"에 문구를 작성해주면 된다.
카카오톡 메시지 전송 설정
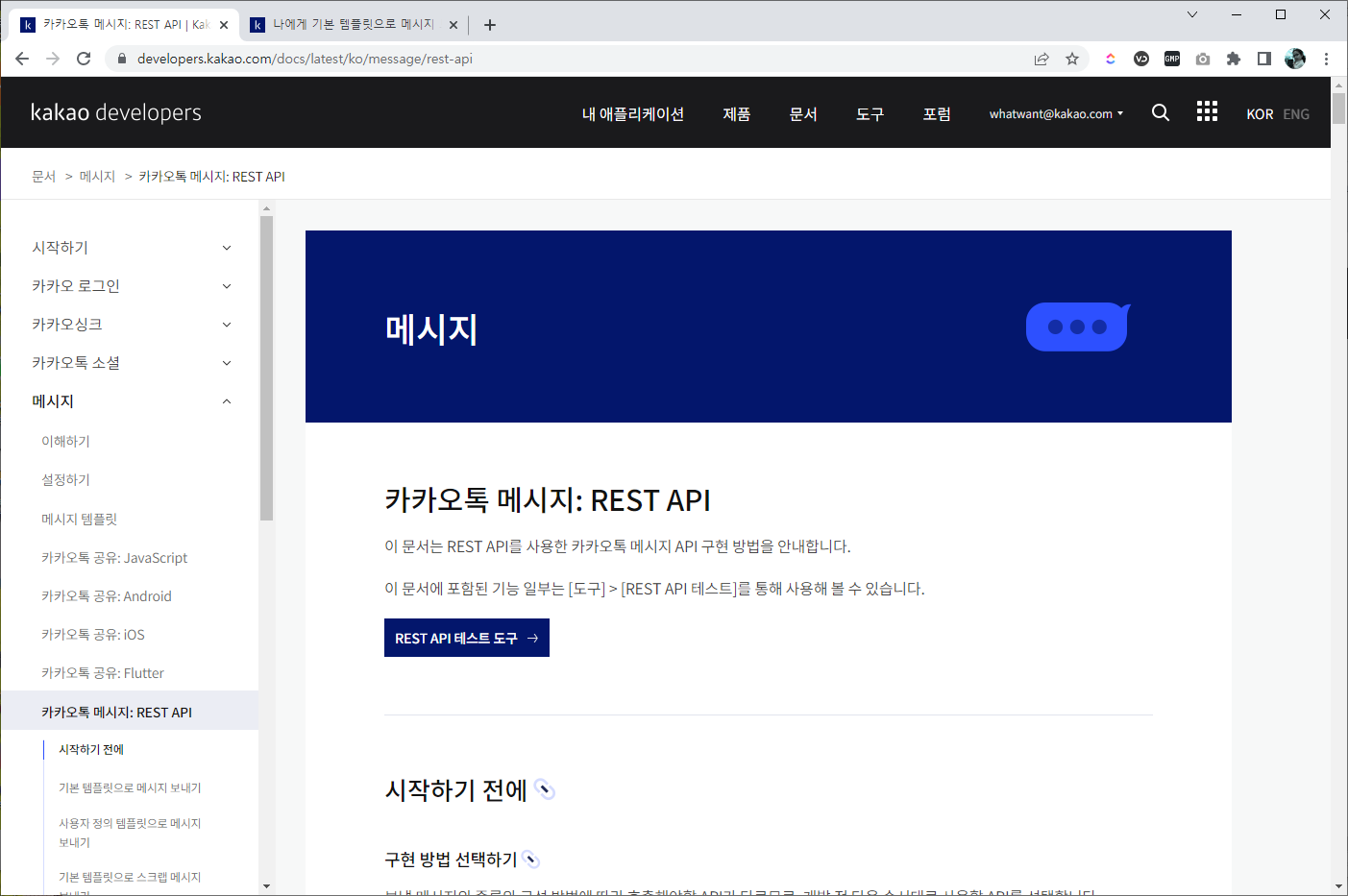
07. 소셜 API 가이드
- 사이트 상단 메뉴에서 "문서" 선택 후, 소셜API가이드 - 메시지 - REST API
소셜 API 가이드
08. REST API 테스트 도구
- "카카오톡 메시지:REST API" 페이지를 보면 바로 보이는 "REST API 테스트 도구"를 클릭하자.
카카오톡 메시지: REST API
09. 나에게 기본 템플릿으로 메시지 보내기
- "REST API 테스트 도구"를 클릭하면 볼 수 있는 화면이다.
나에게 기본 템플릿으로 메시지 보내기
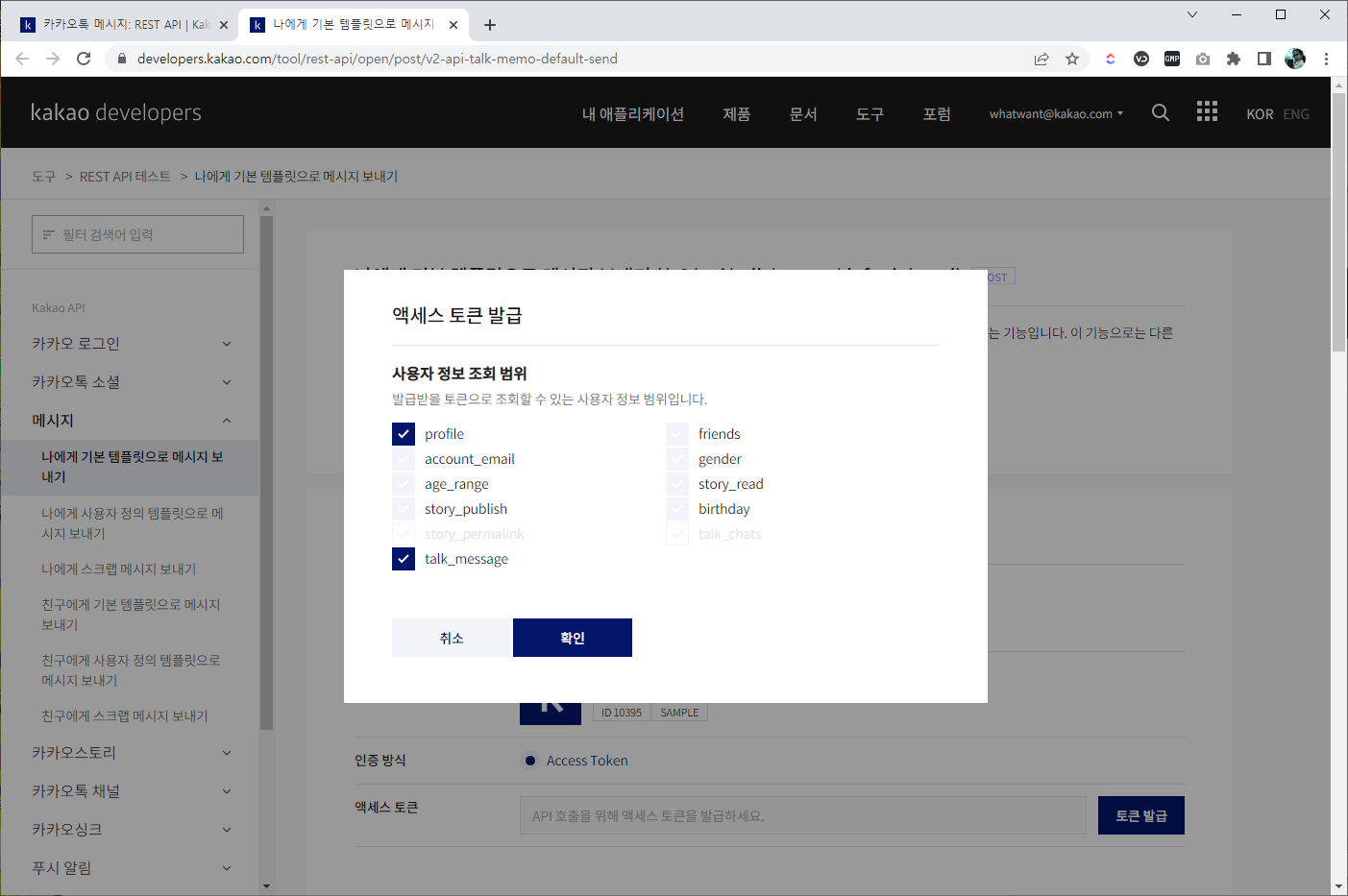
10. 액세스 토큰
- "액세스 토큰" 항목에서 "토큰 발급" 눌러 주자.
- 아래 화면에서 보이는 것과 같이 진행하면 된다.
토큰 발급
- 확인을 누르면 동의화면이 나온다. 동의 해주면 된다.
동의하기
11. 명세 확인하기
- 페이지의 하단 부분을 보면 "명세" 부분을 볼 수 있다.
- "template_object"의 타입 부분에서 "Text"를 클릭해 주자.
명세
- 메시지의 종류라고 생각하면 되고, 지금은 "Text" 형식으로 메시지를 보내고자 하기에 이렇게 한 것이다. - 아래와 같은 형식으로 사용할 수 있다는 것을 확인할 수 있다. . {"object_type":"text","text":"Hello World !!!","link":{}}
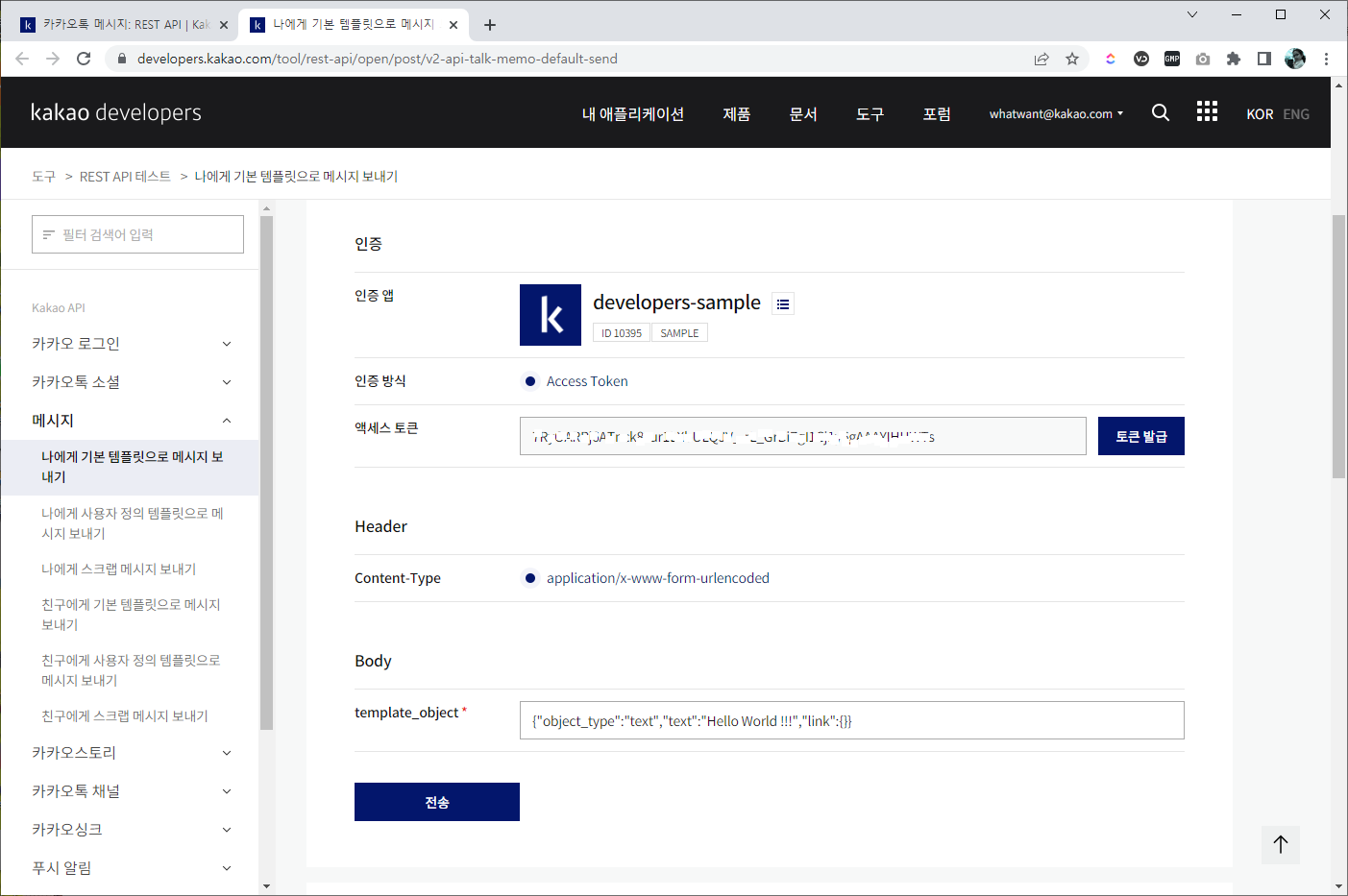
12. 전송
- 페이지의 위로 올라가서 Body 부분의 "template_object" 항목에 입력해주면 된다.
Windows/macOS 환경에서도 docker를 사용하기 때문에 비슷하게 동작하지 않을까 한다.
1. Persistent Volume
Redis가 in-memory data-store 솔루션이지만,
안정적 운영을 위해 메모리에 있는 데이터를 디스크에 쓰는 2가지 옵션을 제공한다.
① RDB (Redis Database) : 지정된 시간 간격으로 스냅샷을 파일로 저장
② AOF (Append Only File) : 모든 작업을 기록, 서버가 시작할 때 이 기록을 읽어서 데이터 재구성
어떤 옵션을 사용하더라도 데이터 저장이 되는 곳이 필요하고
보다 수월한 백업 등의 작업을 위해 docker volume 공간을 따로 구성하도록 하겠다.
# 리스트 확인 $ docker volume ls
# 생성 $ docker volume create [name]
# 상세 조회 $ docker volume inspect [name]
volume
2. Redis Config
접근 가능한 IP를 지정하고, 인증을 위한 패스워드를 넣는 등의 환경 설정을 위한 config 파일을 작성해보자.
또한 config 파일은 host에서 관리할 수 있도록 하겠다.
# 어떤 네트위크 인터페이스로부터 연결할 수 있도록 할 것인지 관리 (여기에서는 Anywhere) bind 0.0.0.0
# 사용 포트 관리 port 6379
# Master 노드의 기본 사용자(default user)의 비밀번호 설정 requirepass [사용하고자 하는 비밀번호]
# Redis 에서 사용할 수 있는 최대 메모리 용량. 지정하지 않으면 시스템 전체 용량 maxmemory 2gb
# maxmemory 에 설정된 용량을 초과했을때 삭제할 데이터 선정 방식 # - noeviction : 쓰기 동작에 대해 error 반환 (Default) # - volatile-lru : expire 가 설정된 key 들중에서 LRU algorithm 에 의해서 선택된 key 제거 # - allkeys-lru : 모든 key 들 중 LRU algorithm에 의해서 선택된 key 제거 # - volatile-random : expire 가 설정된 key 들 중 임의의 key 제거 # - allkeys-random : 모든 key 들 중 임의의 key 제거 # - volatile-ttl : expire time(TTL)이 가장 적게 남은 key 제거 (minor TTL) maxmemory-policy volatile-ttl
# DB 데이터를 주기적으로 파일로 백업하기 위한 설정입니다. # Redis 가 재시작되면 이 백업을 통해 DB 를 복구합니다.
save 900 1 # 15분 안에 최소 1개 이상의 key 가 변경 되었을 때 save 300 10 # 5분 안에 최소 10개 이상의 key 가 변경 되었을 때 save 60 10000 # 60초 안에 최소 10000 개 이상의 key 가 변경 되었을 때